背景
今日はバックエンド関連。
これまでバックエンド(主にDBアクセスまわり)は、ほぼJavaでしか書いたことがなかったので、
node.jsでDB(Postgresql)にアクセスする際には、どんな方法があるのか簡単に調べてみる。
ついでに、接続先のDBがAWSのRDS(Aurora/Postgresql)だった場合に、現時点ではどういう構成が最適なのかについても調べてみようと思う。
実装
まずは、node.jsでDB(Postgresql)にアクセスする際の実装(コーディング)方法について調べて試してみる。
調査
ネットを漁って軽く調べてみた感じ、以下の2つのパターンがありそう。
- ORマッパーとしてSequelizeというライブラリを利用してDBにアクセスする
- pg(node-postgres)を直接使って、自分でSQLを書いてDBにアクセスする
参考)
https://sequelize.org/
https://node-postgres.com/
ネット上の記事を見る限り、Sequelizeを使うケースのほうが多いような印象(まぁやりたいこと次第なんでしょうが)。
また、ORマッパーは他にもライブラリがあるようですが、Sequelizeが主流のようです。
検証
Sequelizeを使うパターンと、使わずに直接pg(node-postgres)を使うパターンで、それぞれシンプルな実装を試してみる。
準備
以下からPostgresqlをダウンロードしてインストール。
https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
今回はWindows x86-64の12.3を選択。
保存先以外はすべてデフォルトでインストールした。
次にexpress環境の用意。
まずはsequelize用。
> mkdir sequelize
> cd sequelize
> yarn init
> yarn add express
すべてデフォルトのままの設定。
プロジェクト直下に以下のように記述したシンプルなindex.jsを作成。
constexpress=require("express");constapp=express();app.get("/",function(req,res){res.send("Hello World!");});app.listen(3000,()=>console.log("Example app listening on port 3000!"));起動。
node index.js
http://localhost:3000/
にアクセスして確認すると「Hello World!」が表示される。
同様にpg(node-postgres)用のexpress環境も用意しておく
> mkdir node-postgres
... 省略 ...
フォルダ名(プロジェクト名)以外は全部同じ設定なので省略。
sequelizeで実装
sequelizeとpgをインストールしておく。
sequelizeでpgを利用するっぽいのでpgのインストールも必要。
> yarn global add sequelize-cli
> yarn add sequelize
> yarn add pg
sequelizeコマンドが簡単に使えるようにpackage.jsonにスクリプトを追加しておく。
..."scripts":{"sequelize":"sequelize"},...sequelize用に初期化。
> yarn sequelize init
以下のようにフォルダとファイルが作成された。
|- config
|- config.json
|- migrations
|- models
|- index.js
|- seeders
config.jsonは以下のようになっており、環境ごとのDBの接続設定を記載する模様。
{"development":{"username":"root","password":null,"database":"database_development","host":"127.0.0.1","dialect":"mysql","operatorsAliases":false},"test":{"username":"root","password":null,"database":"database_test","host":"127.0.0.1","dialect":"mysql","operatorsAliases":false},"production":{"username":"root","password":null,"database":"database_production","host":"127.0.0.1","dialect":"mysql","operatorsAliases":false}}設定を書き換え。
{"development":{"username":"postgres","password":"postgres","database":"database_development","host":"127.0.0.1","dialect":"postgres","operatorsAliases":false},...}usernameやpasswordはpostgresqlインストール時に設定したものを指定しているが、本来は別途作成したユーザー(ロール)を指定すべきなので注意。あと、postgresユーザーのpasswordもまじめに考えるように!!
データベースの作成
> yarn sequelize db:create
pgadmin4で確認してみると、config.jsonで設定した名前でデータベースが作成されている。
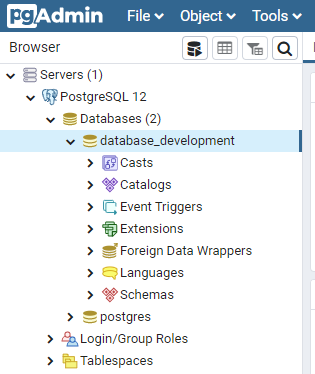
続いてモデルを作ってみる。
> yarn sequelize model:create --name TestClass --attributes attr1:string
この時点でDBにテーブルが作られるわけではなく、モデル定義ファイルと、マイグレーションファイルが、それぞれmodelsフォルダとmigrationsフォルダに作成される。
models以下に自動生成されたtestclass.jsは以下。
'use strict';module.exports=(sequelize,DataTypes)=>{constTestClass=sequelize.define('TestClass',{attr1:DataTypes.STRING},{});TestClass.associate=function(models){// associations can be defined here};returnTestClass;};migrations以下に自動生成された{yyyymmddhhmmss}-create-test-class.jsは以下。
'use strict';module.exports={up:(queryInterface,Sequelize)=>{returnqueryInterface.createTable('TestClasses',{id:{allowNull:false,autoIncrement:true,primaryKey:true,type:Sequelize.INTEGER},attr1:{type:Sequelize.STRING},createdAt:{allowNull:false,type:Sequelize.DATE},updatedAt:{allowNull:false,type:Sequelize.DATE}});},down:(queryInterface,Sequelize)=>{returnqueryInterface.dropTable('TestClasses');}};以下のコマンドでDBが更新されテーブルが作成される。
yarn sequelize db:migrate
pgadmin4で確認してみる。
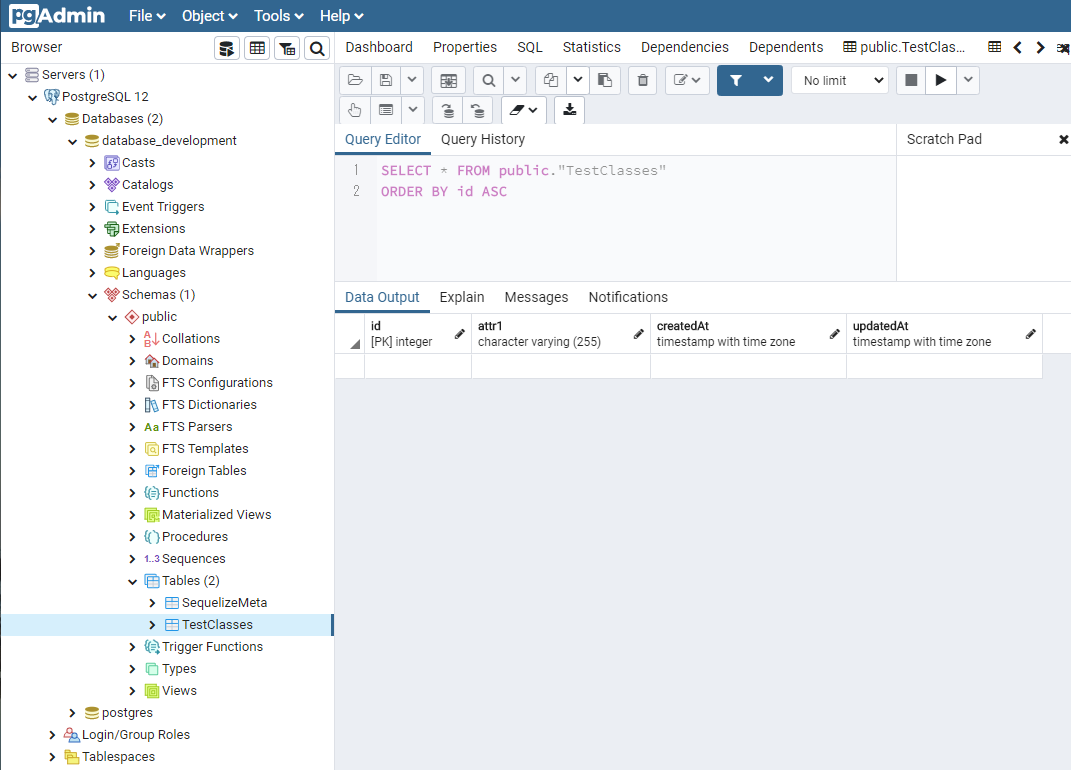
TestClassesというテーブルが追加されている。
適当に"TestClass"という名前を指定したのに、"TestClasses"となっていて、ちゃんと末尾に「es」を付けて複数形にしているのが凄い。
レコードを追加してみる。
index.jsを以下のように書き換える。
constexpress=require("express");constapp=express();constdb=require("./models/index");app.get("/",function(req,res){res.send("Hello World!");});app.post("/create",function(req,res){db.TestClass.create({attr1:"test",}).then(()=>{res.send("Data Created.");});});app.listen(3000,()=>console.log("Example app listening on port 3000!"));requireの1文とapp.post部分のコードを追加しただけ。
サーバー起動
> node index.js
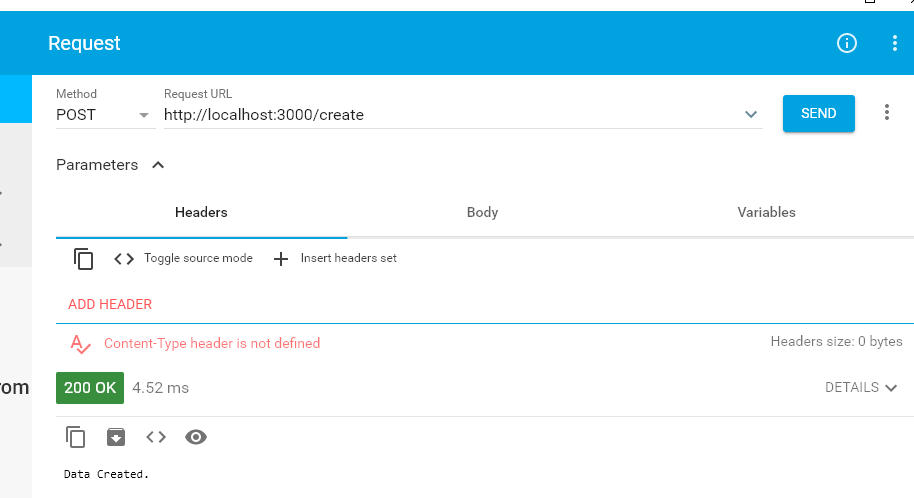
chromeの拡張ツール「Advanced REST client」で動作確認。
http://localhost:3000/createにPOSTリクエストを送ってみる。
pgadmin4でデータを見てみる。
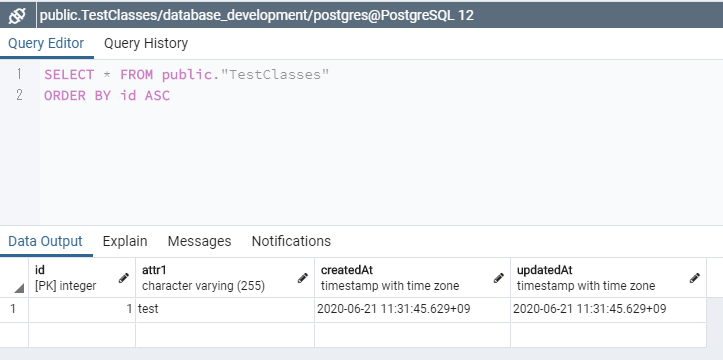
ちゃんとレコードが追加されていました。
簡単ですね。
pg(node-postgres)で実装
続いて、pg(node-postgres)を使ってレコード追加してみようと思う。
とりあえず、準備であらかじめ作成しておいたpg(node-postgres)用のプロジェクトに移動しておく。
> cd node-postgres
pg(node-postgres)をインストールする。
> yarn add pg
DBやテーブルは先ほどsequelizeで作成したものをそのまま利用することにする。
index.jsを以下のように書き換え。
constexpress=require("express");constapp=express();constpg=require("pg");varpgPool=newpg.Pool({database:"database_development",user:"postgres",password:"postgres",host:"localhost",port:5432,});app.get("/",function(req,res){res.send("Hello World!");});app.post("/create",function(req,res){varquery={text:'INSERT INTO public."TestClasses" (id, attr1, "createdAt", "updatedAt") VALUES($1, $2, current_timestamp, current_timestamp)',values:[10000,"test"],};pgPool.connect(function(err,client){if(err){console.log(err);}else{client.query(query).then(()=>{res.send("Data Created.");}).catch((e)=>{console.error(e.stack);});}});});app.listen(3000,()=>console.log("Example app listening on port 3000!"));面倒くさい処理を書いてないのでコードとしてはそんなに長くなってないが、
それでも、テーブル名の前にスキーマ名「public」を付けないとエラーになったり、
「createdAt」と「updatedAt」をダブルコートしないとエラーになったりと、いくつかハマりポイントがあった。
本来ならば、さらに色々と自前で書く必要がある。
例えば、idに固定で10000を入れている部分をシーケンスから取得するような処理にしないと、2回目の実行で一意制約違反となる。
この処理はsequelizeを使えば勝手にやってくれているし、createdAtやupdatedAtも自動的に入れてくれている。
とりあえず、サーバー起動して確認。
> node index.js
こちらも「Advanced REST client」で動作確認。
http://localhost:3000/createにPOSTリクエストを送ってみる。
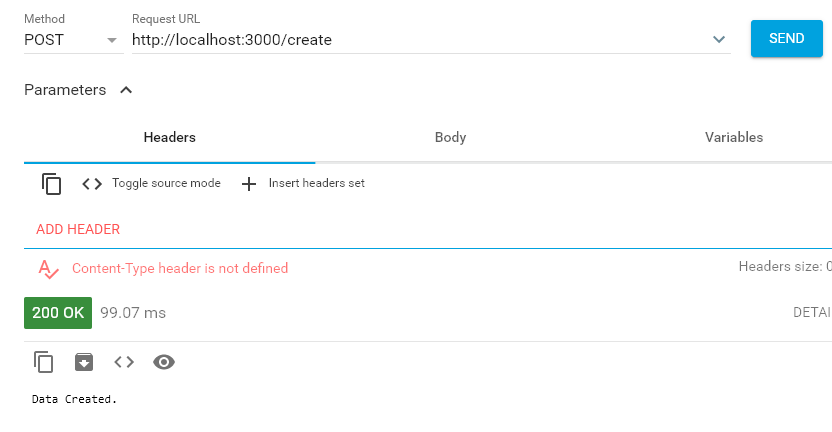
pgadmin4でデータを見てみる。
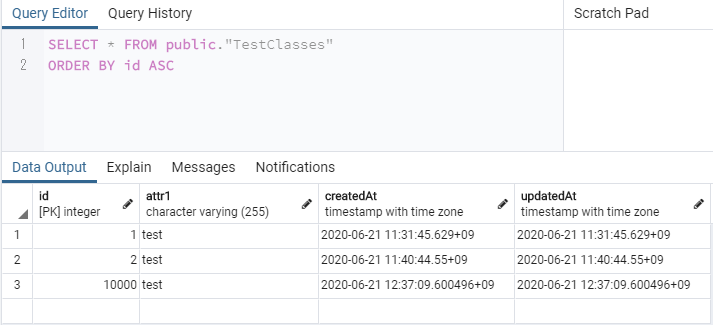
一応、レコードの追加には成功した。
とりあえず、レコード追加のみ試してみたが、それだけでも結構面倒くさい。
これに加えて、sequelizeでは数コマンドの実行だけでやっていたテーブル作成等の作業も、pg(node-postgres)だけを使うのなら、手作業でやるか、自分で実装しておく必要がる。
まとめ
実際に使ってみて、基本的にはsequelizeを使ってやっていくのが楽なのかなという印象。
sequelizeベースで開発して、sequelizeの機能に無いような特殊なことをやりたい場合は、直接、pg(node-postgres)を使って実装する感じかな。
sequelizeは他にも色々出来そうなので、今度試してみようと思う。
システム構成 (Amazon RDS接続時)
AWS上で接続先のDBがAmazon RDS(Aurora/Postgresql)だった場合のシステム構成についての調査。
(話がガラッと変わりますが。。)
調査
以下の3つのパターンが一般的かなと思う。
- EC2 → RDS
- ECS(fargate) → RDS
- Lambda → RDS
1のEC2パターンは今更感があって特に面白くもないので、個人的には選択肢としては最後かな。
2のECS(fargate)パターンは無難な選択といったイメージ。固有の問題が発生したという記事はあまり見かけない。ただ、ものすごくシンプルなサービスで利用するには大げさ過ぎる気もする。
3のLambda パターンについては、リクエスト単位でコネクションを張ってしまい、同時接続に耐えられないという問題が発生するため、これまでだったら、Lambda → RDSのパターンはそもそも"無し"だったんだけど、RDSプロキシというサービスがでてきて、この問題は最近では解決できるっぽい。
(とはいえ、RDSプロキシは「プレビューである事に起因した変更が発生する可能性があるため、本番ワークロードにはこのサービスを使用しないでください」と公式に書いてあるので、現時点(2020/6)では検証でしか使えない。)
さらに、Aurora ServerlessのData APIによっても最大同時接続数の問題に対応できるらしい。
(ただ、こちらもAurora Serverless自体にいくつか制約があるので使用には注意が必要。)
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-serverless.html#aurora-serverless.limitations
ということで、現在では、単純に、アンチパターンだからLambda → RDSは無し、というような感じでは無くなってきていることが分かった。
もう少し具体的な要件で選択していく必要がありそう。
ECSとLambdaを比較した記事だと、小粒のサービスはLambdaで中規模以上はECSといった記述をよく見かける。
Lambdaで大規模なサービスを実現しようとした場合に問題となりそうな制約がいくつかあるので、その辺りだろう。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/gettingstarted-limits.html
上記公式サイトに書いてあるLambdaの制約のうち、同時実行数(1000)やストレージ(75 GB)、VPCのENIの数(250)は、サポートに拡張してもらうことができるが、関数のタイムアウト(15分)やデプロイパッケージサイズ(50MB)、tmpの容量(512MB)などは変更できないので、サービスによっては問題になりそう。
500MB以上のコンテンツを処理する可能性があるとか、そこそこ時間のかかるバッチ処理などを実行する必要がある場合などはLambdaの選択は危険そう。
まとめ
結局、どれを選択するかは要件次第という感じだけど、中規模以上のサービスで、後々、制約で苦労したくないなら、ECS(Fargate)を選択しておくのが無難といったところでしょうか。
(RDS接続というより、単純なLambdaとECSの比較になってしまいましたが。)