はじめに
- Amazon Transcribeは音声データをテキスト化する(文字起こしとも言われる)サービスです
- 音声ファイルを準備してバッチ処理するタイプと、音声をストリーミングして、リアルタイム(逐次的に)処理するタイプがあります
- 日本語については、2020年11月にリアルタイム処理タイプに対応しました
- AWSコンソール上ではブラウザの音声をTranscribeへストリーミングすることで機能を確認することができます。レスポンス良くテキスト化されます
- 実際の業務等ではマネジメントコンソールで使うことはなく、アプリケーション等に組み込むことになると思います
- ということで、サンプル的にストリーミング処理を実装してみました
- そして自分への備忘も兼ねて処理内容の解釈を記述します
- なお、SDK v3はpreviewなので、これからリリースされる正式バージョンと異なる(動作しない)可能性があります
環境
- Ubuntu 20.04 on WSL2
- Node.js v14.15.4
- AWS SDK for JavaScript version 3(preview)
サンプルコード
下記コードをタタキ台として説明します
実行手順
オーディオファイルを準備する
- バッチ処理ではなくリアルタイムストリーム処理、と言ったわりには音声ファイルを準備します
音声入力部分も何らかのストリームにする想定ですが、今回はTranscribeとのストリーム部分にフォーカスし、シンプルにしました
- (手元ではKinesisVideoStreamからの音声をTranscribeへパイプできることまで確認しています)
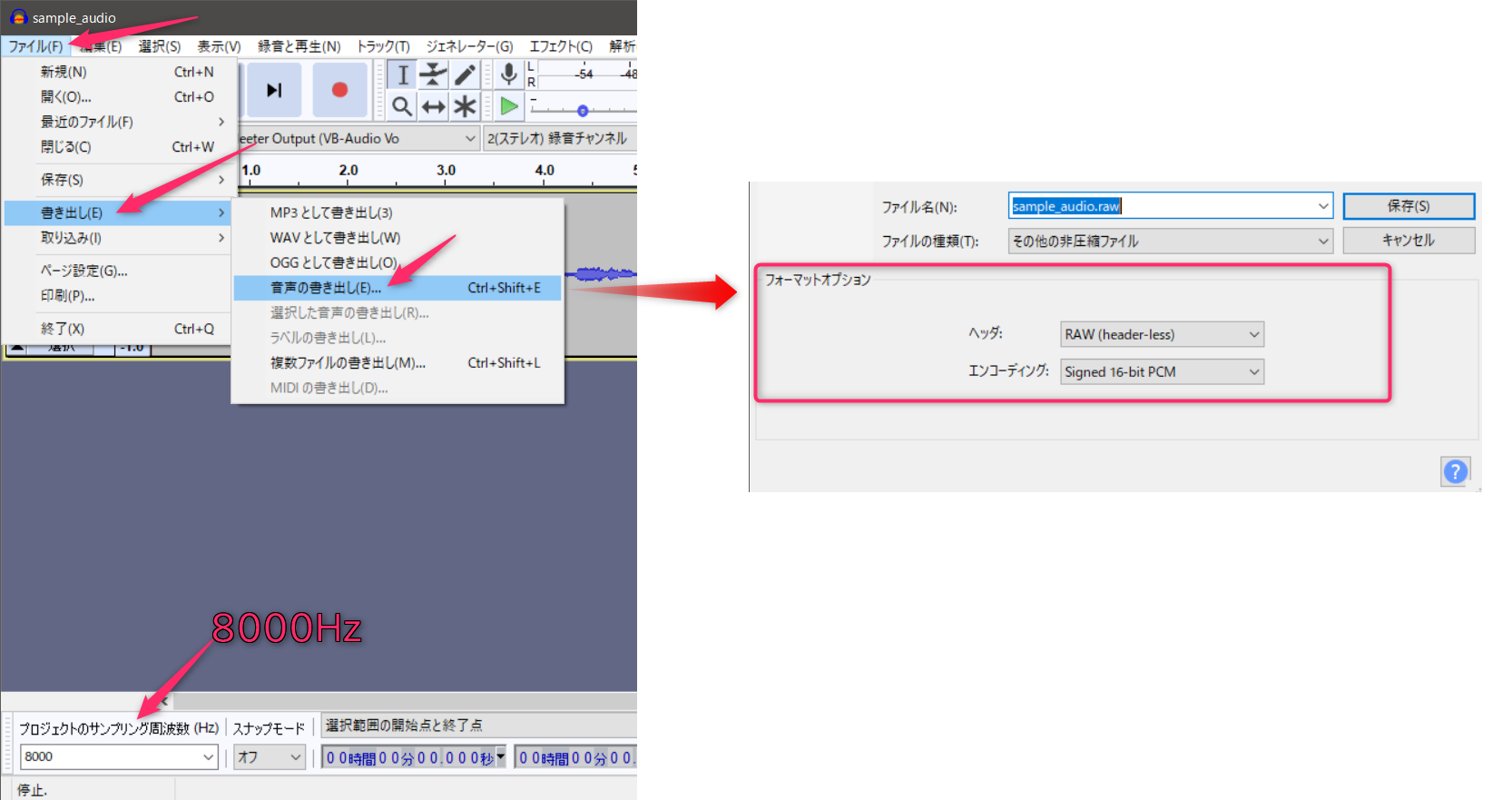
オーディオファイルの仕様
- 符号付き16ビット PCM 8KHz RAW(ヘッダ無)
- 指定がある場合はリトルエンディアンを選択
Audacityを利用して変換するのが簡単です
実行環境の準備
- Node.jsの環境作成
- 各自準備してください
- githubからソースファイルを手元へコピー
git cloneなどで
- パッケージインストール
npm install
実行
- ニュース動画の音声で試してみました
- 下記のようになります
- 音声が30秒ぐらいで、処理時間も30秒+αかかります
- アナウンサーの発声ということもあってか、正確にテキスト化されています
来月 な の か?部分が正確には来月七日ですが、他は誤変換もなく素晴らしい精度です
$ node transcription.js sample_audio.raw
0.08: きょう 東京 都心 は ぽかぽか 陽気 と なり 最高 気温 は 昨日 より 十 一 度、 以上 高い 十 八、 七 度 と か
8.39: 四 月 中旬 並み の 暖か さ と なり まし た
11.98: 江戸川 区 の 葛西 臨海 公園 に は 多く の 家族 連れ の 姿 が。
17.54: 東京 都 で は 緊急 事態 宣言 の 解除 が 予定 さ れ て いる 来月 な の か? まで
23.15: 上野 動物 園 や 葛西 臨海 水 族 園 など 都立 の 動物 園 や 水 族 館 を 臨時 休業 に し て い ます
コードの解説
const parseTranscribeStream...部分
- Transcribeからのレスポンス解釈部です
- Transcribeからのレスポンスオブジェクトを表示用に編集しています
IsPartial == trueの場合は変換途中を示していますので表示から省いています- 条件を外して実行してみると挙動がわかると思います
const audioSource = createReadStream部分
- 音声ファイルを読み込みしています
- highWaterMarkで一度に読み込むサイズを1KBに抑えています
- 大きいサイズを送信するとTranscribe側がエラーを返すことがあります
const audioStream = async function*部分
- 音声ファイルのデータ片を所定のオブジェクト形式に変換しています
const command = new StartStreamTranscriptionCommand部分
- Transcribeとのリアルタイムストリーム開始コマンドを作成しています
- 日本語、PCM形式、8KHzであることを伝えています
- 入力は前段で定義したストリームを指定しています
- 処理が開始すると、入力ストリームから順次データを受け取り、処理する記述です
const client = new TranscribeStreamingClient部分
- Transcribeとのリアルタイムストリーム開始リクエストクライアントを作成しています
- パラメータ
requestHandlerでセッションタイムアウトを5秒指定しています- これを指定しないと音声データ送信が終了しても5分ぐらい通信が切断されません
- SDK内部でコネクションプールしていますが、データ終了時にクローズせず、プールしたままになっているようです
- SDKはまだpreviewなので改善するかもしれません
- パラメータ
const response = await client.send(command)部分
- Transcribeとのリアルタイムストリーム開始リクエストしています
- SDK v3では基本的に「コマンド作成」して、client.send()する記述になるようですね
const transcriptsStream = Readable.from(response.TranscriptResultStream)部分
- Transcribeからのレスポンスを受け取るストリームを宣言しています
transcriptsStream.pipe(parseTranscribeStream).pipe(stdout)部分
- ストリームをパイプで接続しています
- Transcribeからのレスポンスを冒頭で記述したレスポンス解釈部へ
- レスポンス解釈部のアウトプットを標準出力へ
まとめ
- Node.jsの非同期ストリーム処理によってシンプルに実装できる印象です
- そのぶん、どこで何が処理されているか理解しておかないとハマるかもしれません
- この実装だと、HTTP/2 Streaming動作になると思います
- 実は SDK v2で WebSockets Streamingも試していたのですが、途中でv3に気づいて移ってきました
- あまり詳しくないのですが、HTTP/2ストリーミングだと送信ごとに毎回署名してるようなので効率は落ちるのでしょうかね

