モチベーション
参考に挙げたMediumの記事を読んだので、その内容を実際に試してみました。
はじめに
Node.jsの特徴としてシングルスレッドであることが挙げられます。そのため、CPU負荷の重い処理をさせると、スレッドがブロックされてパフォーマンスが低下するので、そのような処理はNode.jsには不向きとされています。どうしても重い処理をしたいときは、マルチスレッドやマルチプロセスを用いることもできます(参考)が、いずれも重大な欠点があります。
マルチスレッドの問題
Node.jsにおけるマルチスレッドでは、基本的にlibuvが提供するthreadpoolからスレッドを取得して使うことになると思います。しかし、libuvのthreadpoolは最大で128個(既定で4個)のスレッドしか供給できません。さらに、libuvが提供するスレッドは、ファイル操作の非同期処理にも使われます。例えば、ローカルファイルの読み書きを行う場合は勿論、ドメイン名をIPアドレスに変換するresolve処理でも(/etc/resolv.confなどを読み込む必要があるので)スレッドが使用されます。そのため、threadpoolのリソースが枯渇し、スレッドが空くまで処理がブロックされ、パフォーマンスの低下を招く未来が容易に想像できます。Node.jsはC10K問題に対する銀の弾丸としての役割を期待されながら、C128問題に悩まされる結果となってしまいます。
マルチプロセスの問題
別プロセスを使用するとC10K問題が再燃します。クライアント数が増えるに従い、使用されるプロセス数も増加し、いずれ上限(linuxの場合32767個)に達してしまいます。また、プロセス数が増えるとコンテキストスイッチのオーバーヘッドが無視できなくなり、全体のパフォーマンスが低下します。さらに、各プロセスがファイル操作やネットワークアクセスを行う場合、プロセス毎にファイルデスクリプタを用意する必要があるため、こちらも資源の枯渇が心配されます。
シングルスレッドで重い処理を行うには?
やはり、シングルスレッド内でも重い処理を行う必要がありそうです。その場合、その処理が他の処理を長時間妨げないことが求められます。こういう処理のことをノンブロッキング(非同期)処理と呼ぶのでした。そうです!シングルスレッドであっても、重い処理を非同期で実行できれば大きな問題は起きません。さらに、あくまでもシングルスレッドなので、C10K問題に対しても(ある程度は)有効なはずです。
処理を非同期化するためには、Node.jsがどのように非同期実行をサポートしているのか理解することが重要です。
Node.jsのスクリプト実行手順
nodeコマンドでjavascripファイルを実行すると、まずトップレベルのコードが実行されます。トップレベルコードでは、非同期処理の実行などにより、イベントループにタスクを追加していきます。トップレベルコードがファイルの最後まで実行されると、イベントループが開始され、トップレベルコード(やイベントループで実行したタスク内)で追加された待機中タスクが実行可能なものから順番に処理されていきます。そして、イベントループ内で処理すべきタスクがなくなると、プログラムが終了します。このように、タスクをとりあえずイベントループに追加し、実行可能なものから次々と実行していくアーキテクチャをReactorパターンといいます。
例えば、次のスクリプトの実行を考えてみます。
例題
setTimeout(()=>console.log('timeout'),1000)// 1秒待つ// 実行結果// timeoutこのスクリプトをNode.jsは次のように実行します。
- トップレベルコードである
setTimeout関数を実行 () => console.log('timeout')というタスクをイベントループに追加- トップレベルコードが終了したのでイベントループ開始
- 実行可能なタスクをポーリング(ie. 検索して見つからなければ待機を繰り返す)
- (約1秒経過)
- 実行可能なタスク
() => console.log('timeout')を発見 () => console.log('timeout')を実行- イベントループにタスクがないのでプログラムを終了
もう少し複雑な例も考えてみます。
例題2
setTimeout(()=>{console.log('1st timeout')setTimeout(()=>console.log('2nd timeout'),1000)},1000)setTimeout(()=>console.log('3rd timeout'),1500)// 実行結果// 1st timeout// 3rd timeout// 2nd timeoutこのスクリプトをNode.jsは次のように実行します。
- トップレベルコードである
setTimeout関数を実行 - 1stタスクをイベントループに追加
- トップレベルコードである
setTimeout関数を実行 - 3rdタスクをイベントループに追加
- トップレベルコードが終了したのでイベントループ開始
- 実行可能なタスクをポーリング(ie. 検索して見つからなければ待機を繰り返す)
- (約1秒経過)
- 実行可能なタスクを発見
- 1stタスクを実行
- 2ndタスクをイベントループに追加
- (さらに約0.5秒経過)
- 実行可能なタスクを発見
- 3rdタスクを実行
- (さらに約0.5秒経過)
- 実行可能なタスクを発見
- 2ndタスクを実行
- イベントループにタスクがないのでプログラムを終了
非同期実行タスクの実行順序
ここまででNode.jsにおける非同期実行の手順を概観しました。その中で中核的な役割を担っていたのがイベントループです。
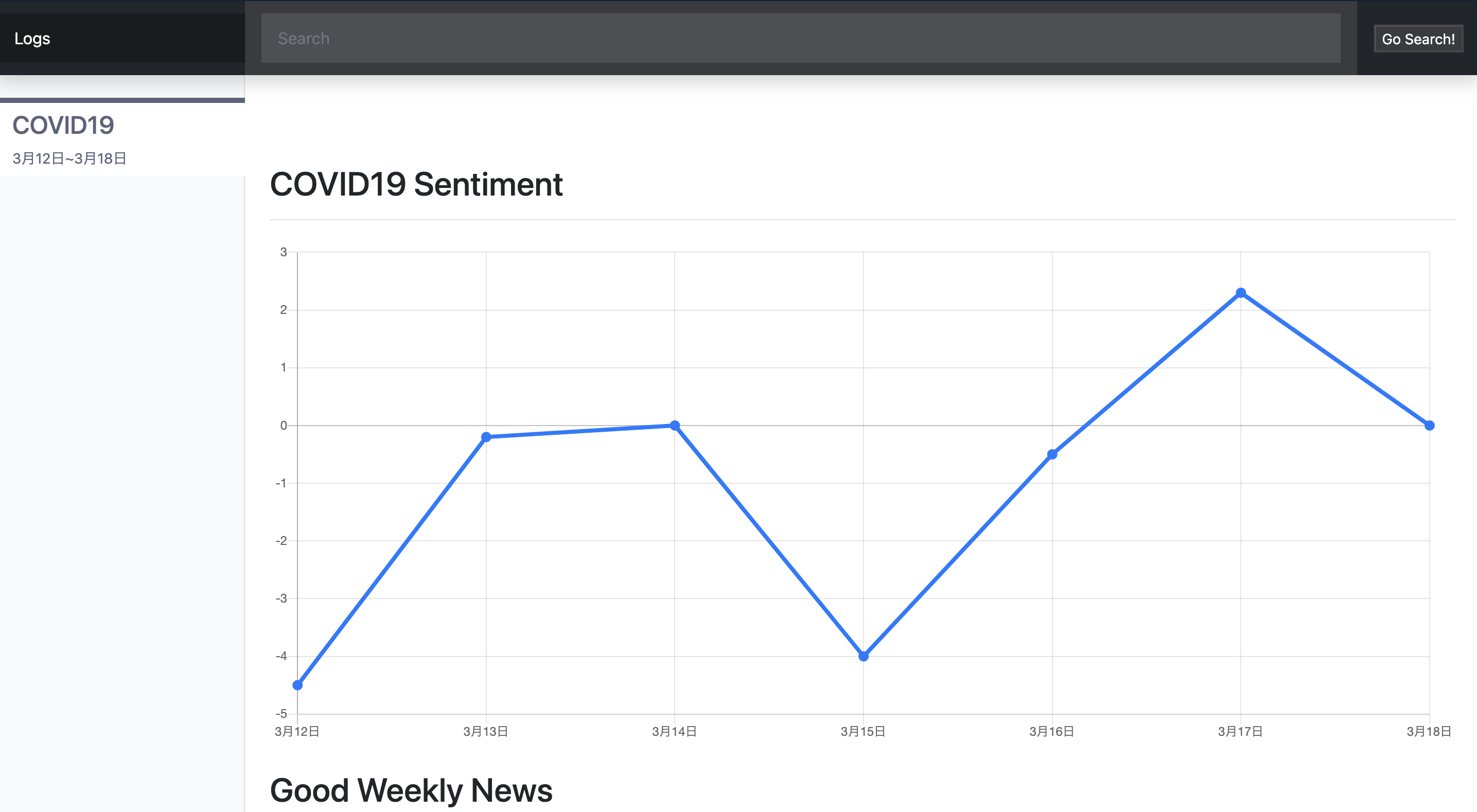
![image.png]()
(Event Loop and the Big Pictureより引用)
前項では、単に「タスクをイベントループに追加する」と言いましたが、イベントループ内でタスクが追加できる場所は次の6種類あります。どの場所にタスクが保管されるかは、そのタスクがどのように(eg. どの関数で)イベントループに追加されるかによります。
- timeout (
setTimeout/setInterval) - IO (ノンブロッキングIO)
- Immediate (
setImmediate) - IOのclose
- process.nextTick
- Promise
イベントループにおいて「待機中タスクが実行可能なものから順番に処理されていく」際の順番は、タスクの保管場所によって決まります。
タスクの6つの保管場所は二種類に分けることができ、1~4に保管されるタスクをマクロタスク、5~6に保管されるタスクをマイクロタスクと呼びます。マクロタスクは1->2->3->4の順番で実行され、マイクロタスクは5->6の順番で実行されます。また、マイクロタスクは個々のマクロタスクの合間(イベントループ開始時を含む)に実行可能なタスクがまとめて実行されます。(註)
例えば、次のスクリプトを実行してみます。
例題
setImmediate(()=>console.log('immediate 1'))// 3番に追加Promise.resolve().then(()=>console.log('promise'))// 6番に追加setImmediate(()=>console.log('immediate 2'))// 3番に追加process.nextTick(()=>console.log('nextTick'))// 5番に追加// 実行結果// nextTick// promise// immediate 1// immediate 2イベントループ開始時には、3番、5番、6番にタスクが追加されており、いずれも実行可能な状態となっています。3番はマクロタスク、5番と6番はマクロタスクの保管場所でした。そのため、まずは5番と6番にあるタスクが5->6の順番でまとめて実行されます。つぎに3番のタスクが実行されます。3番のタスクの終了後、マイクロタスクが検索されますが、見つからないため、引き続き3番のタスクが実行されます。その後、マイクロタスク->マクロタスクの順に検索されますが、いずれのタスクも見つからないため、プログラムが終了します。
(*) setTimeout関数を用いても良かったのですが、setTimeout関数は独特な挙動(註)をするため、例ではsetImmediate関数を用いました。
重い処理の非同期化
Node.jsの非同期実行の仕組みが分かったところで、本題である処理の非同期化をどう実現するか考えます。
シングルスレッドで並行化を行うには、いわゆる時分割方式を採れば良さそうです。例えば、今から100ミリ秒は処理Aを行い、次の200ミリ秒は処理Bを、その後150ミリ秒はまた処理Aを行う・・・という具合に、一つのスレッドを時間軸で二つの処理に分割すると、二つの処理を擬似的に並行実行できます。
時分割方式の要点は、実行する処理を途中で切り替えることです。これはイベントループを使うと実現できます。先程の例で説明すると、処理Aから処理Bへの切り替えを行うには、処理Bのを行うタスクをあらかじめイベントループに追加しておき、処理Aの続きを行うタスク(これを継続と言います)をイベントループに追加して処理Aを取り敢えず終了します。すると、Node.jsは実行可能なタスクを検索し、処理Bを行うタスクを発見して実行します。そして、処理Bでも途中で同じことを行えば、また処理Aの実行を再開することができます。
次に考えるのは、処理の途中で継続をイベントループに追加する方法です。これまで紹介してきたように、イベントループにタスクを追加する方法はいくつかあり、どの方法で追加したかによって実行順序が変わるのでした。
今回の並行化の目的は、重い処理がそのほかの処理を妨げないようにすることでした。そのため、継続はイベントループにマクロタスクとして追加される必要があります。
マイクロタスクはマクロタスクの合間に"まとめて"実行されるのでした。つまり、マイクロタスク内で新たにマイクロタスクをイベントループに追加した場合、次のマクロタスクを実行する前に、新たに追加したマイクロタスクが実行されてしまいます。そのため、もし継続をマイクロタスクとして追加することにすると、重たい処理全体が終わるまでマクロタスクの実行が完全にストップしてしまいます。マクロタスクの実行が止まると、例えば、httpリクエストを受け付けることが出来なくなってしまうので、非常に困ります。(この方法でも、重たい処理を複数個並行実行することはできます)
マクロタスクとしてタスクを追加する関数として、setTimeout、setInterval、ノンブロッキングIO、setImmediateを紹介してきました。setTimeoutやsetIntervalは補足で説明している理由により、動作が不安定になる可能性があります。また、IO処理ではないので、ノンブロッキングIOは使えません。そのため、ここではsetImmediateを使うのが最適です。
実装
実装例として、フィボナッチ数を求めるスクリプトを並行実行させることを考えます。フィボナッチ数を求めるプログラムを愚直に再帰で書くと、計算量は2^nと非常に大きくなります。
実装例
// 通常バージョンfunctionfib(n){if(n<=1)returnnelsereturnfib(n-1)+fib(n-2)}// 並行バージョンfunctionfib_im(n,callback){setImmediate(()=>{if(n<=1)callback(n)elsefib_im(n-1,x=>fib_im(n-2,y=>callback(x+y)))})}実際に実行して比べてみます。通常の処理がブロックされているかを確認するために、同時にsetInterval関数を実行します。
通常バージョンを実行
conststart=newDate()setInterval(()=>{constinterval=newDate()console.log(`interval: ${interval-start}`)},500)fib(40)constend=newDate()console.log(`end: ${end-start}`)// 実行結果// end: 1589// interval: 1601// interval: 2118// interval: 2628// interval: 3142// interval: 3647 実行結果を見ると分かる通り、フィボナッチ数を求める処理が終了するまでsetIntervalで追加したタスクは実行されていません。つまり、他の処理がブロックされています。
並行バージョンを実行
conststart=newDate()setInterval(()=>{constinterval=newDate()console.log(`interval: ${interval-start}`)},500)fib_im(30,()=>{constend=newDate()console.log(`end: ${end-start}`)})// 実行結果// interval: 501// interval: 1000// interval: 1500// interval: 2000// interval: 2500// interval: 3000// interval: 3500// interval: 4000// interval: 4500// end: 4998// interval: 5013// interval: 5520 並行バージョンでは、フィボナッチ数が求まる前でも、setIntervalで追加したタスクが実行されています。つまり、フィボナッチ数を求める処理が他の処理をブロックしていない(ie. ノンブロッキング)ことが分かります。
このように、setImmediate関数を処理の間に挟むことによって、メインスレッドで重い処理を実行したとしても、そのほかの処理をブロックすることはありません。
オーバーヘッド
しかし、setImmediate関数を入れることによって、フィボナッチ数を求める処理のパフォーマンスが大きく低下してしまいました。通常バージョンでは、40番目のフィボナッチ数を求めるのに約1.6秒かかるのに対し、並行バージョンでは、たった30番目を求めるのに約5秒もかかっています。
対策として、setImmediate関数を常に入れるのではなく、時々入れるだけにします。では、どのようなタイミングでsetImmediate関数をいれるのが良いのでしょうか。それは、setImmediate関数を入れることによるオーバーヘッドとsetImmediate関数を入れないことによるブロッキングを天秤にかけることを意味します。今回の場合は、0.5秒に1回setInterval関数で登録した処理を行いたいので、ブロッキング時間は0.1秒くらいであって欲しいです。なので、処理時間が0.1秒を超えないぎりぎりのところでsetImmediate関数を入れるのが最適です。
実装例(error)
letsince=0functionfib_im(n,callback){constgo=()=>{if(n<=1)callback(n)elsefib_im(n-1,x=>fib_im(n-2,y=>callback(x+y)))}constnow=newDate()if(since==0)since=nowif(now-since>100){setImmediate(go)}else{go()}}// 実行結果// RangeError: Maximum call stack size exceeded一見よさげですが、実行するとMaximun call stack size exceededエラーが発生します。これは、関数の再帰呼び出しをfib_im(n-1, x => fib_im(n-2, y => callback(x+y))という形で行っているために、再帰呼び出しされた関数が全て同一のコールスタックに積まれるためです。つまり、コールスタックのサイズは最大で2^nに達してしまいます。
ちなみに、前項の並行バージョンの実装がこのエラーを出さなかったのは、setImmediate関数を挟むとコールスタックが解放されるためです。実際、今回の実装でも処理時間の閾値を0.1秒から0.01秒くらいに減らすと、setImmediate関数が呼ばれる合間に積まれるコールスタックがシステムの制限内に収まるため問題なく動作します。
処理時間でタスクの中断箇所を決めようとするとコールスタック数が枯渇してしまうので、積まれたコールスタック数でタスクの中断箇所を決めるようにしてみます。
実装例(正常)
letdepth=0functionfib_im(n,callback){constgo=()=>{if(n<=1)callback(n)elsefib_imd(n-1,x=>fib_imd(n-2,y=>callback(x+y)))}if(depth>3000){depth=0setImmediate(go)}else{depth++go()}}// 実行結果// interval: 101// interval: 200// end: 278// interval: 314// interval: 417今回は上手く動作しました。フィボナッチ数を求めるのにかかる時間が約5秒から約0.3秒に大幅に短縮されました。
復習
fib_im関数を単独で呼び出した場合の処理時間は約0.26秒です。
単独呼び出し
conststart=newDate()fib_im(30,()=>{constend=newDate()console.log(`end: ${end-start}`)})// 実行結果// end 262では、このfib_im関数を複数回呼び出すとどうなるか考えてみてください。
複数回呼び出し
conststart=newDate()for(leti=0;i<3;i++){fib_im(30,()=>{constend=newDate()console.log(`end: ${end-start}`)})}// 実行結果// end 743// end 754// end 755答えは、「各処理の処理時間は3倍になり処理は全て同時に終了する」でした。
まとめ
Node.jsのイベントループをうまく活用して処理を並行化することで、メインスレッドで重い処理を行ってもブロッキングしないようにすることが出来ることが分かりました。
最後に復習で示した現象は問題と思われるかもしれませんが、これはマルチプロセスを採用しない限り解決されません。また、setImmediateはコールバック関数を引数に取るので、今回例として挙げたスクリプトでもコールバック地獄が垣間見えます。なんとか、async/awaitで書き換えられないでしょうか。この二点の問題については、また機会があれば続編として記事にしようと思います。
おわり。
補足1
Node.jsのバージョンが11.0以上の場合に限ります。それ以前は、マイクロタスクはマクロタスクの各保管場所の実行可能タスクがすべて終了した毎に実行されていました。
例
setImmediate(()=>{console.log('immediate 1')setImmediate(()=>console.log('immediate 2'))process.nextTick(()=>console.log('nextTick'))})// 実行結果(<11.0)// immediate 1// immediate 2// nextTick// 実行結果(>=11.0)// immediate 1// nextTick// immediate2補足2
Node.jsで次のスクリプトを実行すると、どんな出力が得られるでしょうか。
例
setTimeout(()=>callback('timeout'),0)// 1番に追加setImmediate(()=>callback('immediate'))// 3番に追加マクロタスクは1->2->3->4という順番で実行されるので、
となると予想されますが、実際には、
となる"場合"があります。
これは、setTimeout関数の第二引数に0を渡した(または、第二引数を省略した)としても、timeoutは0秒ではなく1ミリ秒として扱われるためです。そのため、setTimeoutが実行された時点からイベントループでタスクが検索されるまでの間に1ミリ秒未満の時間しかかからなかった場合には、上で示したような実行結果となります。
参考