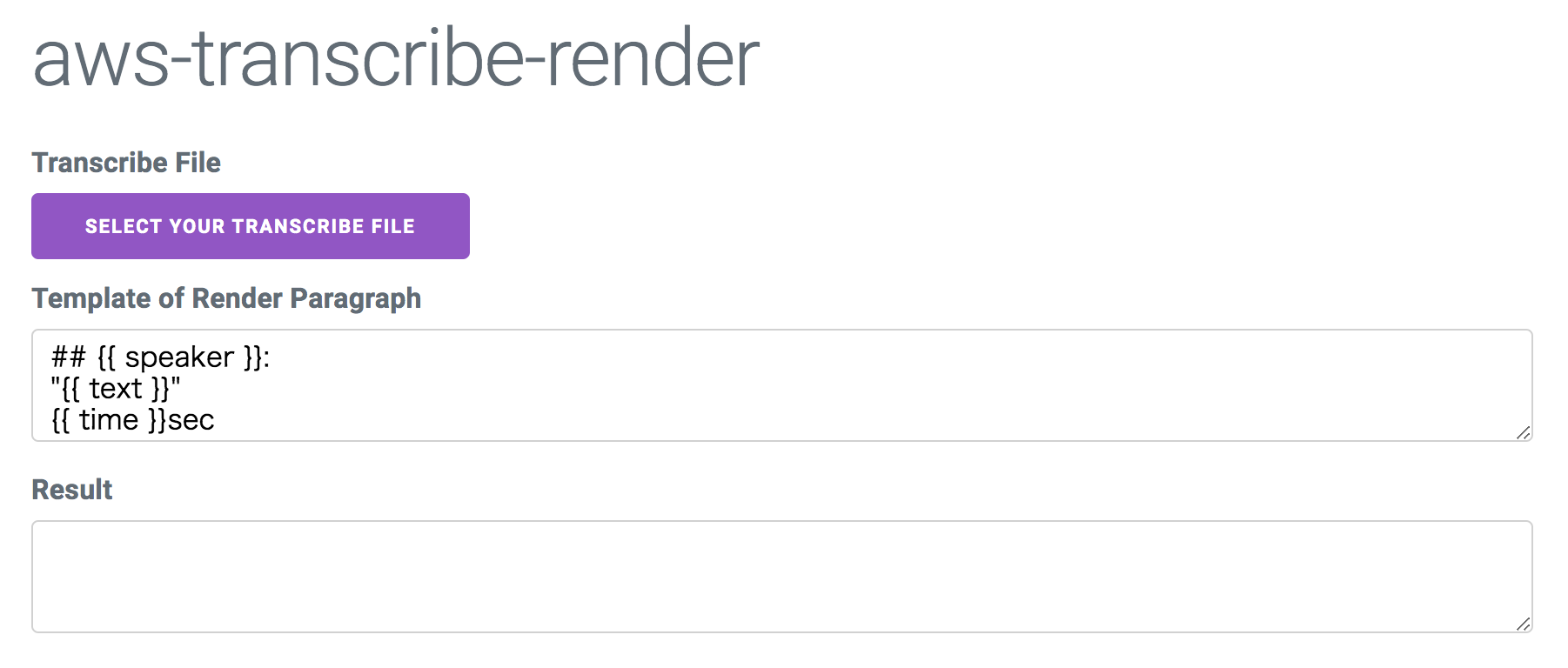
この記事は学園祭のシステム業務に携わった人々などがお送りする「学園祭プログラマーAdvent Calendar 2019」の12日目の記事です。
よかったら他の人の記事も見ていってくださいね!
はじめに
みなさんLINE Messaging APIってご存知ですか?この記事を見ている人ならおおよそ知っている人が多いと思いますが、LINEで自動返信をする"BOT"を作ることができるAPIです。約3年前にリリースされてから様々な機能が追加されてきました。今回の記事はこれを使って学園祭でLINE BOTを作成したことに関するお話を色々していきたいと思います。
自己紹介
自己紹介が遅れました。私、東京大学での秋の学園祭「駒場祭」でLINE BOT関係を担当させていただいた者です。yuukamiと呼んでください…
数年前、ちょうどBOTブーム最盛期?にLINE BOTに出会いまして、BOTで色々遊んだり、高校の文化祭の公式LINEを担当したりしておりました。その後、大学に入学したのち、その場の気分で学園祭の実行委員会の方に入りまして、システム担当の方をやることになりました。そこで、過去の経験などもありまして、LINE BOTの制作に携わった次第であります。
やったこと
端的に言えば学園祭の公式LINEを作りました。最初の方は企画投票を公式LINEでやるので、その機能を作って欲しい、みたいな感じだったのですが、LINE BOT作りが楽しくなってしまっていろいろな機能を入れたくなり、結局企画検索や単純な会話の機能も追加することになりました。
目次
長いので必要な部分だけ読むことをお勧めします。
技術編
- LINE Messaging API
- pm2
- (番外編) chalk.js
- (番外編) express.js router
問題解決編
- 投票機能の困難
- 困難1 : 状態管理
- 困難2 : 条件分岐の多さ
- 困難3 : 一旦対話から離れて別ページへ飛んで対話に復帰する
- 検索機能の困難
- 困難1 : 「もっとみる」の実装
- 困難2 : 「"」と 「’」の扱い
- 会話機能の困難
- 困難1. 対話パターンの多さ
- 困難2. スタンプへの返信
- 開発時の困難
技術編
ここではLINEBOTを作るに当たって必要となった技術的な知見を一挙に書いていきたいと思います。
初めて使ったものも割とあったので、正しい使い方とは異なる場合がありますが、そこはご容赦くださいm(_ _)m
LIFF(LINE Front-end Framework)
一言で言えばWEBページにLINEの機能を少し混ぜられる機能です。
HTMLのscriptでliffのsdkを読み込むことで、ウェブページ上でJSを使ってLINEを使っている人のuserid・プロフィールが取得できるようになったり、トーク画面にメッセージをユーザーの代わりに送ったりできます。
LIFFの公式ドキュメントはこちら
今回での使用例
今回のBOTではLIFFページにアンケートを置いて、最後に送信を押すことでaxiosでサーバーにアンケートのデータをPOSTしつつ、トーク画面に「次へ」のようなメッセージを送信することで、次にある企画投票のフェーズにスムーズに移ることを計画していました。
ただ、駒場祭の直前の頃、この「トーク画面にメッセージを送る機能」が使えないことがわかりました。おそらく、理由としては、11/11のリリースノートにある、「LINEログインを中核とした機能拡張」に向けた改変だと思われます。
私が数ヶ月前に作っていたテスト用LIFFでは「トーク画面にメッセージを送る機能」は使えていました。しかし、いざ駒場祭も近づいてきたことだし本番環境でもその機能を追加しようとした時、そうすることはできませんでした。新しく機能追加することを防いでいるのでしょう。
そのせいで、アンケートから投票までの流れがかなり無理のあるぎこちないものとなってしまいました。みなさん、何かAPIなど開発者が他のものを使う時は急な仕様変更に気をつけましょう…
機能紹介
LINE Developpers の項目を紹介したいと思います。(一部加工しています。)
![スクリーンショット 2019-12-09 0.24.18.png]()
![スクリーンショット 2019-12-09 0.25.02.png]()
LIFF URL
LIFF URLはこのURLにアクセスするとこのLIFFのページが開きますよ、というものです。
変なことを言うと混乱の原因となるので謹みますが、とにかくLIFF URLはここに書いてあるものを利用してください。(私はこれとは違うURLを利用した結果、色々と不具合が起きました…)
サイズ
LIFFは基本的にはLINEアプリ中の内部ブラウザで開かれる利用例が想定されているようで、全面を覆う"Full", 若干上部分が空く"Tall", 半分ぐらいを占める"Compact"がある模様です。
アンケートのようにウェブページ的な利用の場合は"Full"か"Tall"を、トークの途中の要素としての利用なら"Compact"といった使い分けでしょうか。
エンドポイントURL
LIFFページが置かれているサーバーのURLを指定すれば良いです。
LIFF URLを踏んでLIFFのページを開こうとすると、このURLにページをGETしにいく、という感じなのでしょう。
SCOPE
アクセス許可です。現在は"profile"(プロフィールへのアクセス権限)しかないと思います。
昔は"~.write"という、トークへの送信権限が設定できたのですがね…
オプション
LIFFはLINE Thingsと呼ばれるBluetooth機器との連携もできるようです。
scanQRという、LINEについているQRコードを読み取る機能を起動する権限もあるようですが、この機能はiOS版LINEで機能を一時停止している模様です。
Flex design
LINEのMessaging APIに新しく追加されていた機能で、今まではテンプレートの型しか利用できなかったボタンやカルーセルを自由にカスタマイズできるようにする機能です。
(LINE公式ドキュメントよりテンプレートメッセージの例)
![テンプレートメッセージ]()
これがFlexメッセージを使うと
![LINE_capture_597675374.738383.JPG]()
このようにできます。
独自のアイコンを追加したり、ボタンもデザインできたりするので、グッとデザインの統一が可能になります。ただ、書式がJSONやYAMLで、CSSのように見やすくかけないところが欠点だと思います。
Flex Message Simulatorやその続編 Flex Message Simulator(ß)もあるので、一からデザインするのであれば、割と楽だと思います。(このツール、インポートができないので、若干苦労しました。)
pm2
この存在を上司の方から教わりまして、ひどく感動しました。
Node.jsをターミナルの裏で稼働し続けるようにできるものです。
pm2.config.jsonと言うものを作れば、環境変数なども設定できて、
pm2 start pm2.config.json --env <環境名>
を実行すると、<環境名>に紐づけられた環境変数を読み込んで実行できます。
pm2 start <環境名>で稼働開始、
pm2 restart <環境名>でコードを再び読み込んで稼働開始
pm2 stop <環境名>で稼働停止
pm2 logs <環境名>でログの垂れ流し
pm2 monit <環境名>でCPU使用率などの確認
などなど色々機能があります。
詳しくは pm2 公式ページをご覧ください。(すごくかっこいいです。)
ただ、pm2で環境変数を追加した後にrestartをするだけだと、新しい環境変数が更新されないと言う事態が発生したので、ご利用の際はしっかりstopした後もういちどstartするようにした方がいいかと思いました。
(番外編) chalk.js
chalk.jsのサイト
![LINE_capture_596900003.999261_Original.JPG]()
(画像:chalk.jsのサイトより)
個人的に大好きなnpmパッケージです。
上のようにconsoleに色がつけられます。
console.log(chalk.blue.bgRed.bold("あああ"))
とすると赤背景に太字で青文字の「あああ」が表示されます!
consoleがすごく華やかになるのでおすすめです!
あと、普通にエラーなどが見やすくなります。
(番外編) express.js router
今までexpressを使ったことがなかったため、全く慣れていませんが、使えて良かったことを紹介します。
index.js
app.post('/line',line.middleware(lineConfig),(req,res)=>{// ... メッセージの返信処理}LINEのサーバーからメッセージが送られた時はlineの公式のパッケージを利用してメッセージの認証を行います。
ただ、lineのミドルウェアを間に挟む際、データ通信でよく使う、JSONパースの設定
index.js
app.use(express.json())app.use(express.urlencoded({extended:true}));を使うとうまく動きません。
その時に助かったのがrouterです。
index.js
app.use('/other',router_http)のようにすると/otherで送られたリクエストはrouter_httpで捌いてくれるようになります。このrouter_http内で
index.js
router.use(express.json())router.use(express.urlencoded({extended:true}));などとすることで、lineのミドルウェアに干渉することなくJSONパースができました。
expressのルーターを使えば、"/"以下をそれぞれ別のサーバーとして扱う、ということができるので、とても便利ですね。(駒場祭のウェブサイトもそのルーターを使っているみたいです。)
問題解決編
BOT制作にあたって各機能ごとにぶつかった困難と、それをどう解決したかを書いておきます。これからの制作でこれらが少しでも役立つことがあれば幸いです。
1. 開発時の困難
困難1. pm2で環境変数が更新されない
pm2は先述の通り、環境名を使って環境変数を分けて使えるのですが、開発環境でできたものを本番環境にあげようとしたところ、原因不明のエラーが発生しました。開発環境ではちゃんと動く処理が動かないのです。なんでだろうと、本番環境でテストしたところ、環境変数が参照できないと言うエラーでした。
解決法
先述の通り、新しく環境変数を追加した場合は、restartではなく、stop=>startの手順を踏むことが必要なようです。
2. 投票機能の困難
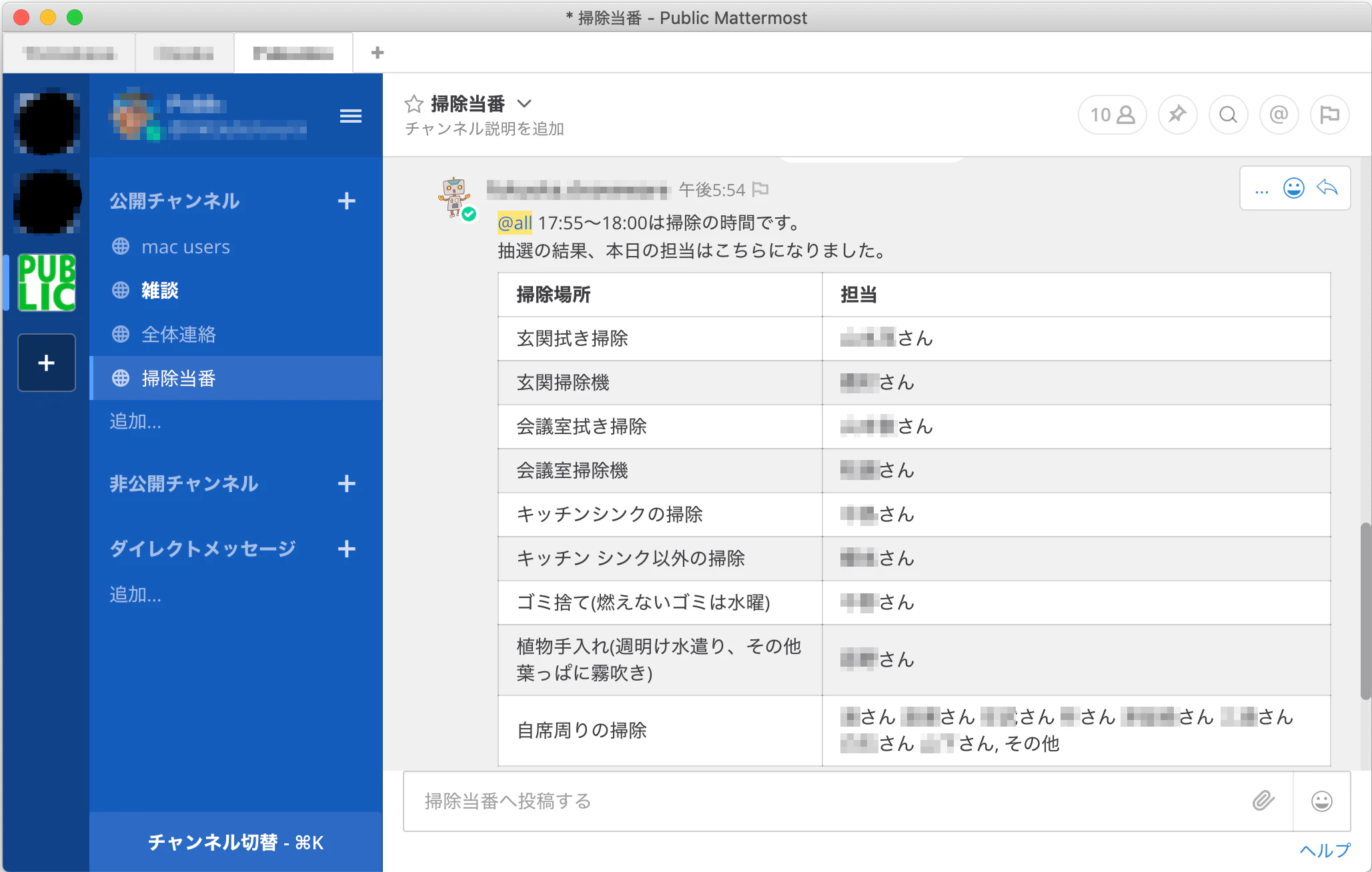
うちの学園祭では来場者の方に気に入った企画のIDを投票していただき、それをもとにランキングを作成し、表彰するというものがあります。投票は投票所でタブレットやコンピュータに入力するのが主流ではあるのですが、数年前から来場者の多数が利用しているLINEを活用して、より気軽に投票ができるようにと、LINE投票が始まりました。
困難1 : 状態管理
LINEをはじめ、ほとんどのBOTではどのような文脈でユーザーが発話してきたかについては知ることができません。そのため、会話の状態管理もこちらでしなければなりませんでした。
(Dialogflowなどの外部ツールを使えば、そのような状態管理は丸投げできるのですが、利用制限などの面から導入はしませんでした。)
解決法
やることはそんなに複雑ではなく、データベースにユーザーIDと状態の番号を一対一で保存しました。ただ、そうすると状態の読み込みが一発話ごとになるので、データベース読み込み回数が大変なことになるのですが、今回使っていたサーバーが非常に強いものだったので、全くそのことを気にせずできました。(サーバー管理者の方ありがとうございます。m(_ _)m)
(もっと大規模なBOTではどのように状態管理を行なっているのでしょうか。このBOTと同じようにデータベースで管理しているのでしょうか。興味が湧きました。)
困難2 : 条件分岐の多さ
投票時には企画IDを入力する必要があるのですが、おおよそ一般の方はそんなIDのことを気にすることなく、「〜をやっていた企画」などというふうに記憶しています。そのため、投票時に企画のIDを検索する機能が必要でした。LINEは対話式に物事が進んで行きますから、投票の流れの中で企画IDの検索機能を入れると状態管理が複雑になってしまいます。これにとても苦しまされました。
解決法
本当は状態管理用のツールを作るべきなのですが、当時の私にそのような能力・時間はなく、とりあえずswitchで大量に条件分岐しました。(力技ですごめんなさい)
例えばユーザーが3と言う状態で「投票」と発話すると〜、「番号を検索」と発話すると〜、「やめる」と発話すると〜、それ以外は〜、などという感じです。
おかげで、投票機能の条件分岐だけで1000行いってしまい、とても管理しづらくなってしまいました。また、「この状態でこうなった場合はどの状態に移るのか」といった遷移の関係が非常に見辛く、そこは失敗した点だと考えています。自分で遷移の関係を図示してみましたが、カオスです。
![IMG_4979.JPG]()
ただ、システムの裏はこのように複雑なことになっていますが、表面はなるべくユーザーのキーボード入力が少なくなるよう多くのボタンを配置したつもりです。
![LINE_capture_596900090.487445_Original.JPG]()
(上のように企画ID以外はなるべくボタンでの操作にしました。)
困難3 : 一旦対話から離れて別ページへ飛ぶ
投票前には来場者の方への簡単なアンケートがあります。そのページを別で作った関係で、アンケートはLINEの対話の中には組み込まず、一つのウェブページに飛ばすことになりました。ただ、それではアンケートの後にある企画への投票のデータとユーザーのデータが結びつかない、また、アンケートをせずに企画への投票に移ることができてしまう、などの問題点がありました。
解決法
そこで利用したのが LIFF(LINE Front-end Framework)というものです。(詳細は技術編を参照)、それを使えばLINEでの対話と連携したウェブページを作成することができます。
ただ、こちらも色々とトラブル続きで、当日まで様々な不具合が発生しており、担当者の方にお多大なご迷惑をかけてしまいました。また、LIFFの機能が直前になってテスト環境と異なることに気づいたため、急遽導線を変更し、少し使いづらくなってしまいました…
![LINE_capture_596899960.155579_Original.JPG]()
上のようにアンケートをしないと企画投票に進めない"風"のデザインにして、アンケートに答えてもらいました。(実際アンケートせずには投票できないようになっています。)
(元々は、LIFFの機能を使ってアンケート画面で「投票へ進む」を押すとそのままトーク画面に戻って接続する予定でした…本当に残念です…)
3. 検索機能の困難
公式LINEと言えばやはり企画検索だと思います。実は駒場祭には検索APIというものが作られていまして、別の記事にもあると思いますが、そこでキーワードを入力すると、個数指定で企画の情報を持ってくることができます。(便利です!担当者の方ありがとうございます。)それを利用して、入力されたキーワードに対して情報を表示する機能を制作しました。ウェブサイトの検索機能も同じAPIを使っているので、情報は同じなのですが、サイトではCSSなどデザインの部分を多く読みこむのでLINEの方がスピードが出せるということを、当日使用していて思いました。今後はその検索スピードの速さを売りにしていきたいですね。
困難1 : 「もっとみる」の実装
検索ワードに対して30件ヒットしたとします。しかし、LINE Messaging APIによればカルーセルメッセージで送ることができる要素は最大10こまでです。前述の通りLINE BOTでは会話の文脈が保存されないので、ユーザーが「もっとみる」を押した時に残りの20個をどう取ってきて、表示したら良いかが問題でした。
解決法
簡単に言えば検索API側の機能とPostbackを利用しました。
これもまた優秀な検索APIに助けられたのですが、検索にはページという概念がありまして、例えばヒット数30で、一ページあたりの個数を10に設定すると、一ページ目を要求すると1~10が、2ページ目を要求すると11~20の企画情報が返ってくるようになっています。それを利用することで、必要十分なデータだけを取得することが可能になりました。(担当者の方ありがとうございます。)
ただ、これだけではまだ完成ではありません。何度も言っていると思いますが、LINE BOTでは文脈が記憶されませんので、今表示されているのが「どういうキーワードで検索した結果の何ページ目か」を記録しなければなりません。データベースにその情報を書き込んでもいいのですが、わざわざそのために列を新しく作るのは躊躇われたので、Postbackという機能を利用しました。これは送信するメッセージにメタ情報的なものを付け加えることができる機能です。
「もっとみる」ボタンのメタデータに「検索ワード」と「次のページ番号」などをPostback用データとして埋め込んでおくことで、ユーザーがそのボタンを押すと、ただのメッセージではなく、Postbackメッセージとしてこちらが受け取ることができます。データを読み込むことでその状況にあった続きの検索結果を返答することができました。
困難2 : 「"」と 「’」の扱い
今回のLINE BOTではFlex Message(詳しくは技術編)というテンプレートのデザインよりも遥かに自由度の高いデザインが可能なメッセージ形式を多く利用したのですが、その記述方式がJSON型で、さらに文言を状況によって変える必要があったため、オブジェクト型を文字列型に変換したり、また戻したりしました。そこで問題になったのが「"」と「'」です。企画名に時々この記号が含まれているのですが、この扱いに非常に苦労しました。
解決法
とはいっても解決法は簡単なものでした。JSON用の引用点は全て「'」を使い、企画名に含まれる「"」を「\\"」(\は2本)に置き換えればエスケープされてうまくいきます。
と言うjsonをテンプレートとして用意します。
データによって{{name部分を変えたいので}}このjsonを文字列として取得します。そしてreplaceで置き換えて、再びJSON parseします
main.js
// kikaku_name は 「event '19 and "20"」です。//データから読み込む時に「"」は邪魔しないはずです。 consttemplate_string="{'name':'{{name}}'}"constkikaku_name=kikaku_name.replace(/"/g,'\\"')constdata=template_string.replace(/\{\{name\}\}/g,kikaku_name)こうするとparse時にエラーを吐かず、さらにLINE からも「メッセージ形式がおかしい」と言うエラーが来なくなりました。("や'をちゃんとエスケープしないとJSONの形が崩れてLINE側が読み込めなくなります。)
result
//data={"name":"event '19 and \\"20\\""}JSON.parseすると"となってしまうのでこのような対策が必要みたいです。
4. 会話機能の困難
LINE BOTの醍醐味の一つは自由な会話だと思います。ということで様々なキーワードに反応できるように工夫しました。また、駒場祭では公式キャラクター「こまっけろ」のLINEスタンプも販売しているということで、それを用いた機能も何かできないかと考えました。
困難1. 対話パターンの多さ
普通BOTなどが会話するときは機械学習などで言葉の表記ゆれや曖昧さを加味して発話の意図を捉えます。ただ、今回はそのようなデータが用意できなかったので、キーワードと返答を一対一対応させることになりました。そこで生じたのがパターンの多さです。トイレというものを表すためにも「トイレ」「便所」「お手洗い」など様々な言葉が考えられます。それら一つ一つに対して返答を考える必要があり、数が膨大となってしまいました。
解決法
同じ意味を表す言葉に対しては同じ返答で良いので、それをまとめられるアイデアを考えました。
結果的に採用されたのは、スプレッドシートにキーワードをカンマ区切りで書き、その隣の列に返答を書き、それをtsv(タブ区切り)でエクスポートした後に、加工してJSON形式の返答例集を自動生成するというものでした。
conversations.spreadsheet内
| 入力 | 出力 |
|---|
| トイレ,お手洗い,便所 | トイレはこちらにあります。 |
== (tsvで出力) =>
トイレ,お手洗い,便所 \t トイレはこちらにあります。
== (「,」でsplitして整理する。) =>
reply.json
[{"トイレ":"トイレはこちらにあります。"},{"お手洗い":"トイレはこちらにあります。"},{"便所":"トイレはこちらにあります。"}]という感じです。
このようにすることで、返答が膨大であってもスクリプト一つ走らせるだけで簡単に返答集が生成されるようになりました。
困難2. スタンプへの返信
これは困難というほどではありません。
スタンプには「こんにちは」などの言葉が書かれており、それに対応する返答を返してあげようという完全に遊んだ機能を作りました。また、この返信にはランダム性を持たせて、複数ある選択肢から一つ選択して返答するという機能も追加しました。
解決法
スタンプにはパッケージIDとスタンプIDが割り振られており、それで区別が可能です。それを利用して、特定のスタンプが送られたときはこのメッセージを返す、というものを作れば簡単にスタンプに対する返信が可能になります。ランダムな返答については返答をカンマ区切りにして上と同じくtsv出力した後、カンマを用いてsplitした後にランダムな数字で配列にアクセスすれば可能です。
以上長くなってしまいましたが、最後まで読んでくださりありがとうございました。
また来年の駒場祭で会いましょう! さようなら!