![スクリーンショット 2019-12-23 0.06.32.png]()
俺「すっげぇいい名前のライブラリ思いついた!!」
俺「npm あるかな?あるかな?」
(カタカタ)
俺「なかった!よっしゃ一番乗りや!!!今すぐ作らないと!!!」
俺「npm init enter enter enter enter npm publishうおおおおおおおいっけぇぇぇ!!!!!!!」
(カタカタカタカタカタカタカタカタッターン)
俺「ミ゜ッ!」
ーーー
おはようございます。本番環境でやらかしちゃった人 Advent Calendar 2019の 23 日目を担当する、@sandessOjisanです。この記事では 思いもよらないものを npm publish したお話を紹介します。
僕は あるとき 色々な会社の仕事を請け負っていた時期があり、そのときの無邪気なnpm publishによって、良くないことをしてしまったというお話しです。このコマンドを叩くといきなり本番環境に上がるので、1ミスが命取りです。僕が何をしでかしたか、ここでだいたい想像ついた方もいらっしゃると思いますが、その方はニヤニヤしながらお楽しみください。あと、ところどころ誤魔化しているのは意図的であり、また現在の所属でのやらかしではありません。
では、やらかしを 2 つと、その対策について紹介します。
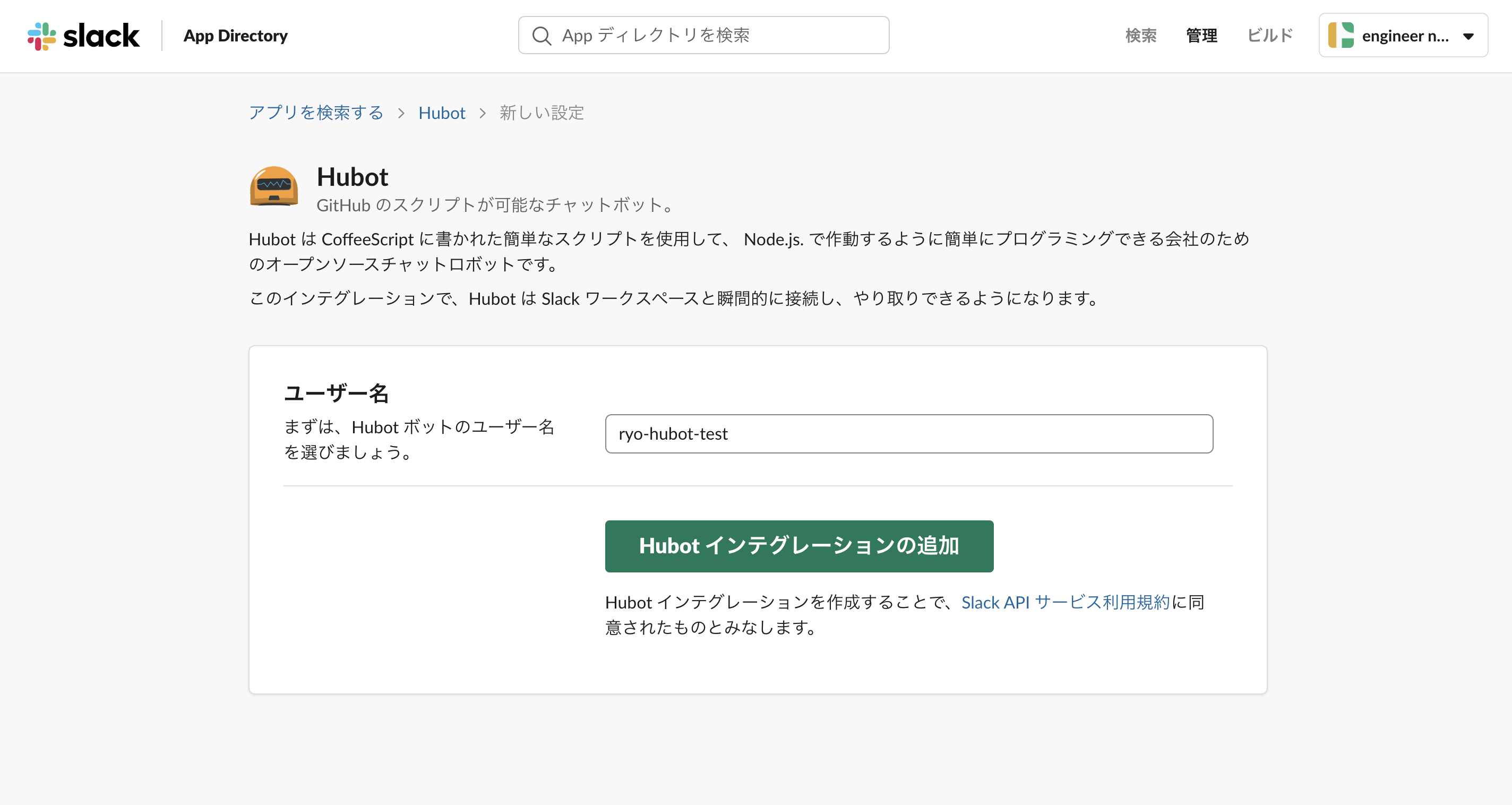
ツールを publish したら、Collaborators に前任者の顔写真が上がった話
npm のざっとした説明
普段 JS を書かない方も読まれていると思いますので、僕がやらかした npm publishが何かについて説明します。npmは Node Package Manager の略で、主に JS プロジェクト のための、パッケージ・ライブラリ管理システムです。 ライブラリは npm registry に登録することで、配布や共有が可能になります。そして、npm publishというコマンドが npm registry に登録するコマンドです。
npm に登録すると、このようなページが作られます。(react の npm ページ)
![react.png]()
このとき、開発者は collaborators として登録されます。
![collaborators.png]()
普通、ここには自分で作った ライブラリ であれば自分のアイコンが表示されるはずです。しかし僕がライブラリを作った時、ここに僕のアイコンはありませんでした。
自分が作ったライブラリの collaborators 欄に前任者の顔写真が載った話
あるとき、某社の某チームにて、ちょっとしたライブラリを作っていました。それはその会社のいろんなプロジェクトから呼び出されるものであり、ライブラリ(node_module)として開発されていました。そして、どうしてか npm 経由で配布していました。1
僕はそのツールをメンテナンスする仕事をしていたのですが、どうしても必要なモジュールがあったので、それを別ライブラリとして開発、publish しようとしました2。このときの publish の方法は、
- 責任者から
npm publish用の共用アカウントの id/password を教えてもらい - それをターミナルに打ち込んで手元から publish する
というものでした。(※そもそもその運用がヤバいだろというツッコミはお控えください。あとこの運用しているところ何個か知っているので、別に珍しい話でもないです。ただ、良くない運用です。)
早速 publish しようと id/password を打ち込んでログインし、npm publishを行いました。どんな風にページができるかたまたま気になったので npm ページで成果物を確認しに行きました。なんとページを開くとそこには前任者の顔写真がありました。
![pose_dance_ukareru_man.png]()
このときプロジェクトの成果物を前任者の顔写真に紐づけてしまったので、
- 会社の看板を背負って、人の顔写真をあげてしまった
- 前任者の顔写真をその名の通りグローバルなインターネットに公開してしまった
というやらかしをしたことに気づき、すごい冷や汗が出てきました。が、責任者や前任者にそのことを報告するとゲラゲラ笑われたので結果的には大丈夫でした。そこで余裕をもって原因を解明してみました。
何がおきたのか
最初は package.json を疑いました。何かをコピペしてきて、author のところも変にコピペしたかなといった風に思って package.json を確認しましたが何も問題はありませんでした。そもそもこの author と collaborars は関係なさそうです。なので、authorである自分の写真が表示されないことはそもそも正常な挙動でした。
さらに調査するために collaborators のところからその前任者のページに飛ぶと、そこには共有アカウントの名前が表示されていました。なんと、そもそもプロジェクトの共有アカウントそのものに前任者の顔写真が紐づいていました。つまり、僕がやらかす前にすでに前任者自らが、共用アカウントに自分の顔写真を紐づけるというやらかしをしていました3。では、どうして前任者は共用アカウントに自分の顔写真を紐づけてしまったのでしょうか。
Gravatar
npm はGravatarというアバター作成サービスをアイコンとして使っています。そして、npm のアイコンは Gravatar からしか登録できません(Issue#12)。つまりアカウント作成時や編集時になんらかのやらかしがあったようです。
![gravatar_small-262x135.jpg]()
共用アカウントを作ったのは前任者です。そしてそのときに 自身の Gravatar と npm のアイコンを紐けてしまったようです。前任者になんで紐づけたかを確認したところ、それは分からないとのことでした。
推測でしかないですが、Gravatar の操作は難しく、前任者があやまった設定をしただけな気がしています。設定は このような手順でやっていくのですが、レーティングの設定や、何を持って別サービスと Gravatar のアイコンを紐づけているのかが不明瞭で、意外と苦戦します。npm は、一般的なサービスと違って、自分で写真をアップしてそれを選択してアイコンとして設定するといったことができません。そのため、なんらかの操作ミスによってこういう事故はおきてしまったのだと思います。
これはまだ笑い話ですが、次は本当のやらかし話です。
個人開発した OSS を A 社のアカウントに紐づけて publish した話
僕はジョークライブラリを npm に publish することが趣味で、日頃から publish しています。先日も ビルド時に俳句を読めるプラグインを publish したり、その前にはgeo cities コンポーネントなどを publish しました。よく友人からは「電子ゴミ職人」 と呼ばれています。
僕は、このようなジョークライブラリを、とある会社のアカウントで publish してしまいました。
なぜ自分以外のアカウントで publish したか
それは様々な会社で npm publishしている関係で、色々な会社のアカウントに npm loginしているからです。そしてそれらの publish をプライベート端末で行っているので、会社のアカウントに login したまま自分の OSS を publish し、自分じゃないアカウントに紐づけてしまったからです。
npm は publish 前に 「このアカウントで publish しますよ y/N」といった確認もないので、いきなり本番環境に publish できてしまいます。そのため、いまどのアカウントでログインしているかを確認しないと、全然関係ない組織に紐づけて publish してしまうということが起き得ます。そして僕は見事にやらかしました。真面目な事業をしている会社のアカウントで、ジョークライブラリ以外の説明ができない名前のライブラリを publish してしまいました。
![chikyu_inseki_syoutotsu.png]()
たまたま、すぐに気づいたので npm unpublishして、責任者に報告と謝罪をしました。その後は、すぐさま再発防止策とその運用フローを用意しました。その再発防止策は記事の終盤で紹介します。
ぶっちゃけ間違って publish しても消せばセーフなのでは?
アウトです。確かにやらかしても npm unpublishすれば消せるので、このケースもやらかしではないかもしれません。ただ、この npm unpublishは時間制限があるので注意が必要です。なんと、公開から72 時間後は消せなくなります。(npm-unpublish)。72 時間たつと、サポートにメールで問い合わせしないといけなく、簡単な道のりではなさそうです4。また、そもそも消しても、消すまでに多少のラグはあり、その間に第三者に見られたり install されると、配信元の信用低下に繋がり兼ねません。
なぜ npm から消せないのか
どうしてこのような厳しいルールになったのか直接的な理由は知りません。ただ、よく言われているのは、left-pad 騒動です。これは、left-padというライブラリが作者の意向で非公開となったとき、それに依存していた他のライブラリのビルドも通らなくなり、その影響が波及し利用者の多い有名サービスのビルドですらできなくなったというものです。また、有名ライブラリが消えるとその名前を横取りしてユーザーに悪意のあるコードを DL させるということもできます。5そういった事故が起きないように、npm 社は package の削除に対して慎重な姿勢になっています。
そういった運営がされる以上、もしあなたが何か npm registry 上で情報漏洩して 72 時間経つと、半永久的にあなたが情報漏洩した事実が記録されます。注意しましょう。
left-pad 騒動について
left-pad の一連の騒動については以下の記事などで解説されています。興味のある方はご覧ください。
[作り話] もし仮に A 社アカウント login 中に B 社 prj のディレクトリで publish したら何が起きるか (情報漏洩者として名が一生涯 npm に刻まれる話)
先ほどの話は、自分で作った OSS を npm で公開した話です。もし仮に、2 社かけもちで仕事をしていて、A 社の成果物を B 社に紐づけて publish したらどうなっていたでしょうか。情報漏洩です。
npm は、その気になれば、
- A 社アカウントでログイン
- B 社プロジェクトの dir 階層に移動
- package.json の名前を適当に書き換える
npm publish- A 社の名前で B 社のソースコードを全世界に公開する
ができてしまいます。
これは完全に悪意を持った行為ですが、先ほどの僕のように無邪気なnpm publishで同じようなことが起きることも十分に考えられます6。npm publishは慎重に使うべきコマンドです。
惨劇はなぜおこってしまったのか
npm publish が悪い?
内心では、「何も確認もなく npm publish できてしまうの、ちょっとカジュアルすぎるのでは!?!?」と思っています。とはいえ、npm に限らずこの手のツールはこの手のやらかしをできてしまうので、一般的なプロセスとも言えます。結局は使う側が注意しなければいけません。7
軽い気持ちで publish する自分が悪い
では、なぜ僕はすぐにちゃんとした確認もせずに pubilsh してしまったのでしょうか。それはすぐデプロイしたくなる力が働いたからです。
とりあえず deploy したくなる
- パッケージ名 は早い者勝ちなので、とりあえず v0.0.1 ですぐ publish したい
- 本番へのデプロイが安定するまでの修正は、本番に対するトライアンドエラーになる
1 番目はともかく(マナー的にもよくない気がするし、可能ならnamespace使えばいい8)、2 番目はどうしても起きる問題なため、カジュアルな deploy はできた方が良さそうです。その上でどう対策していけば良さそうでしょうか。
二度と惨劇を起こさないためにどうしたのか
結局のところ、個人が自分の裁量だけで publish できるのがよくないのだと思います。
publish 権限を個人に割り当てるのをやめよう
まずは個人端末からの publish を制限すべきだと思います。
そして、そもそも OSS にするつもりがないものを npm で管理するのはやめましょう。Github をレジストリ代わりに使うこともできます。(npm install で github のリポジトリからインストールする)
対策に向けて ~個人開発でも CI/CD サーバーを用意しよう~
結論から言うと CI/CD から publish しようということです。そもそもの話なのですが、ローカルからレジストリに push ってやらない行為だと思っています。Node.js に限らずレジストリにライブラリを登録していくとき、普通は CI/CD サーバー からやっているはずです。9
ところが個人レベルでは CI/CD を使って module を publish している人は意外と少ないのではないでしょうか。そこで、個人レベルでも CI/CD サーバーを導入する対策方法について紹介します。ズバリ、Github Actions を使いましょう。
npm publish の仕組み
npm publish のためには、まず npm に登録して、npm login する必要があります。これまではこの無邪気なログインでやらかしをしていました。
認証と token
npm loginすると、 ~/.npmrcというファイルに token が保存されます。npm publish時はこの token を利用して認証をクリアしています。そのため試しにこのファイルを適当な文字で書き換えてみると publish ができなくなります。
この token はコピーしちゃえば持ち出せるので、これを CI/CD サーバーに配置すれば npm publishを行うことが可能となります。
module と package.json
ところで npm publish をしたら何が公開されるのでしょうか。基本的には package.json に書かれている内容が公開されます。特に name と version が重要です。この name はそのまま publish 時の名前になり、version は name ごとに同一なものが存在できません。そのため npm publishするときは適切な名前をつけて、publish ごとにバージョンを変える必要があります。またここで登場する author は collaborators には反映されません。collaborators は npm loginのユーザーに紐づくことに注意しましょう。
Github Actions で対策してみる
原理的には認証トークンの配置と、package.json の記述をすれば CI/CD サーバーからでも npm publishできます。ここでは Github Actions での例を示しますが、Circle CI でも drone といった他の CI/CD ツールでも可能です。
Github Actions はその名の通り、Github が提供している デプロイワークフロー自動化サービスです。Github と連携しているため、 .github/workflow/ 配下に workflow ファイルを設置するだけで CI/CD パイプラインを構築できます。
これは個人レベルでも CI/CD パイプラインを簡単に導入できる素晴らしいものです。これがあれば個人開発中に副業先のソースコードをインターネットにぶちまける危険性を下げることができます。10
workflow で publish を定義
CI/CD パイプラインにおける各種タスクはワークフローファイルという yaml に記述して定義します。
prd のデプロイで publish すればよさそうです。とりあえず、tag が打たれたら、それに該当するコードがビルドされてデプロイされるように設定します。
name:prdon:push:tags:-v*jobs:build:runs-on:ubuntu-lateststrategy:matrix:node-version:[12.x]steps:-uses:actions/checkout@v1-name:Use Node.js ${{ matrix.node-version }}uses:actions/setup-node@v1with:node-version:${{ matrix.node-version }}-name:installrun:|yarn install-name:buildrun:yarn build:prd-name:publishrun:|npm config set //registry.npmjs.org/:_authToken=$NPM_TOKENnpm publishenv:CI:trueNPM_TOKEN:${{ secrets.NPM_TOKEN }}ここでは環境変数として NPM_TOKEN をあらかじめ Github の設定画面で設定しておき、それを config として読み込むようにしています。これは実質的にはログインに相当します。
そして、npm publishを実行しています。
むやみな publish を防ぐワークフロー定義
これでタグ打ちから publish できるようになりましたが、タグ打ちのための手間はかかるので、publish は失敗したくないです。そのためなるべく確実に publish できるように諸々のチェックを master ブランチマージ前に行うようにしましょう。そのワークフローを開発用 workflow として設定を書きます。
name:devon:push:branches:-feature/**-fix/**jobs:build:runs-on:ubuntu-lateststrategy:matrix:node-version:[12.x]steps:-uses:actions/checkout@v1-name:Use Node.js ${{ matrix.node-version }}uses:actions/setup-node@v1with:node-version:${{ matrix.node-version }}-name:installrun:|yarn install-name:licence checkrun:|summary=`yarn license-checker --production --summary`echo $summaryret=`echo $summary | grep -v LGPL | grep -e GPL | wc -l`exit $ret-name:buildrun:|yarn build:devenv:CI:true-name:can i publishrun:yarn run can-npm-publishここでは feature/** や fix/** ブランチへの push があると、publish できるかチェックしています。そして Github 側でこのワークフローが全部通らないと merge できないようにすれば、master ブランチのソースコードは publish の成功確率が上がります。11
ここでは、ライセンスの確認と、バージョン上げ忘れの確認をしています。特にこの can-npm-publishは諸々の確認をしてくれるので便利です。
またやらかした
こちらがやらかなさないプロジェクトとして作っていたものですが、やらかしてます。コミットログを見ればわかると思いますが、やらかしまくってます。例えば、ライセンス違反をして publish をしたり、package 名が規則にあっておらず空振りしたり、namespace で区切ったが access 設定してなくて publish に失敗したり、エントリポイントの path が間違っていて何も import できないなどやらかしています。npm publishが成功したかはどうしても本番でしか確認できないので、stable なデプロイができるようになるまでは本番でやらかす傾向になります。stable にする前はマイナーバージョンなので良い気もしてますが、もしこのタイミングで npm install されると、ユーザー側で不具合がおきる可能性があります。そのため CI/CD サービスを使ったデプロイワークフロー整備も大切ですが、本番だけでこけることも想定した対策も必要です。12