概要
pupetterを使ってAmazon.co.jpから欲しい物リストをスクレイピングする手法のメモです。
下記のように欲しいものリストのIDを指定する事で、商品名と価格、商品IDを取得できる形にします。
// 欲しい物リストのIDを指定constitemList=awaitamazonWishScraper.getProductInfo('hogehoge');console.log('itemList',JSON.stringify(itemList));[{"title":"ProductA","price":3278,"productID":"429711111X"},{"title":"ProductB","price":1234,"productID":"429711112X"},]背景
Amazonの欲しいものリストをスクレイピングで取得する例は、何点か見つかりましたが、紹介されているものの多くは、現在は使えないものでした。
というのも以前は、一定数商品が存在する場合にはページの切り替え行なっていましたが、現在はAjaxで同じページ内で画面をスクロールする事で非同期に読み込む方法に変更されたためです。

こうなると、GETリクエストを投げてHTMLの解析だけではなく、ブラウザの操作をエミュレートして、スクロールを行うようなヘッドレスブラウザが必要になります。
今回は、puppeteerというヘッドレスブラウザを使用して実現します。
前提
MacOS 10.15.3(19D76)
VS Code 1.42.1
node.js v12.14.1
puppeteer 2.1.0
実装
実装方法の検討
画面スクロール
前述の通り、一定数以上の商品が登録されている場合にはページのスクロールを行いデータを読み出す必要があります。
puppeteerにはブラウザ内で任意のjsが実行可能なので、画面をスクロールさせる処理を実行します。
スクロールの停止(全商品読み込み完了の検知)
スクロールを続けた後に、全ての商品が読み込み終わった事を検知する必要があります。
欲しい物リストの末尾には、下図のようなリストの末尾を示す情報が表示されます。
この部分のタグが検知されたら、全ての商品の読み込みが終わったと判断します。
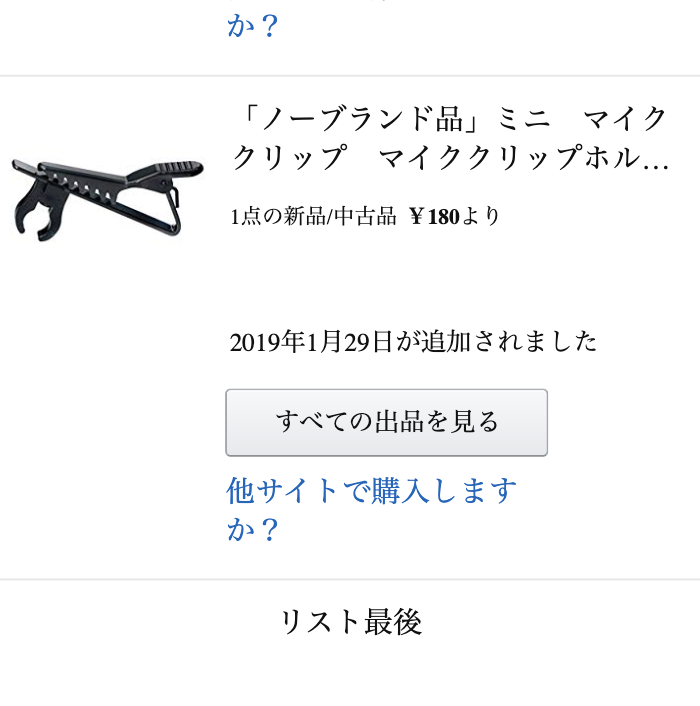
<divclass="a-row center-align-text full-width-element"><divid="no-items-section-anywhere"class="a-section a-spacing-none">リスト最後
</div></div>商品情報の取得
全ての情報が画面に描画されたのならば、後は通常のスクレイピングと同様にHTMLタグを解析するだけです。
実装コード
欲しいものリストサイトへのアクセス
puppeteerを初期化して、欲しいものリストのIDからURLを特定してアクセスします。
今回は表示される情報量を減らし、スクレイピングの効率を上げるためにデスクトップPCではなく、iPhone(スマホ)をシミュレートします。
この部分の処理は、puppeteerの基本的な動作方法ですので詳細は割愛します。
constpuppeteer=require('puppeteer');constdevices=require('puppeteer/DeviceDescriptors');constiPhone=devices['iPhone 8'];consturlbase='https://www.amazon.co.jp/hz/wishlist/ls/';asyncfunctiongetProductInfo(wishListId){constbrowser=awaitpuppeteer.launch({headless:true,args:['--no-sandbox','--disable-setuid-sandbox']});try{constpage=awaitinitPage(browser);// 欲しいものリストのURLを開くawaitpage.goto(urlbase+wishListId);// スクレイピング(中身は後述)returnawaitscrapePage(page);}catch(err){console.error(err);throwerr;}finally{browser.close();}}asyncfunctioninitPage(browser){constpage=awaitbrowser.newPage();awaitpage.emulate(iPhone);returnpage;}欲しいものリストサイトへのアクセス
実装方法の検討で説明した通り、
- リストの末尾が見つかるまで画面をスクロールする
- HTMLをquerySelectorで解析する
といったことを実施します。
querySelectorでのデータの切り出しは、生のHTMLを確認しながら商品ブロック単位で情報を取得するように対応しています。
asyncfunctionscrapePage(page){returnawaitpage.evaluate(async()=>{// スクロールでの移動距離と待機間隔msconstdistance=500;constdelay=100;// リストの末尾が検知されない限りループするwhile(!document.querySelector('#no-items-section-anywhere')){// 500pxずつスクロール移動して、100ミリ秒待機するdocument.scrollingElement.scrollBy(0,distance);awaitnewPromise(resolve=>{setTimeout(resolve,delay);});}// 全ての商品の表示が終わったらスクレイピングを実施constitemList=[];// 商品の情報のBOX単位でデータを切り出す[...document.querySelectorAll('a[href^="/dp/"].a-touch-link')].forEach(el=>{constproductID=el.getAttribute('href').split('/?coliid')[0].replace('/dp/','');consttitle=el.querySelector('[id^="item_title_"]').textContent;letprice=-1;constpriceEle=el.querySelector('[id^="itemPrice_"] > span');if(priceEle&&priceEle.textContent){price=Number(priceEle.textContent.replace('¥','').replace(',',''));}itemList.push({price:price,title:title,productID:productID});});returnitemList;});}まとめ
簡単にはですが、puppeteerを使ってAmazonの欲しいものリストから情報を一覧取得する法法を紹介しました。
スクロールをシミュレートし、非同期で読み込まれるデータの取得を実現しています。
こういったユーザの操作が必要となる処理に関しても、puppeteerを使う事で簡単に実現ができました。