今さらながらCloudWatch SyntheticsでWebサイトの監視をしたのでまとめます。
この記事の内容
- CloudWatch Syntheticsのために手動でS3バケットとIAM Roleを作る
- ローカル環境にPuppeteerをインストールしてNode.jsのコードを書く
- Googleのトップページに「猫 wikipedia」を入力して検索する
- トップにWikipediaの記事が出てこなかったら異常事態なのでスクショを撮ってCloudWatchでアラートを上げることにする
- このコードをCloudWatch Syntheticsに持って行ってCanaryを作成する
きちんとした環境構築などはしていません。非常に意識の低い内容となっています。。
まず最初に:勝手にバケットやIAMを作ってほしくない
最初のセットアップで s3://cw-syn-results-999999999999-ap-northeast-1というS3バケット、 CloudWatchSyntheticsRole-canary-123-4567890abcdeというIAM Roleが勝手に作られるのでちょっと気分が良くありません。手動で作ることにします。(気にしない人は次へ進みましょう)
IAM RoleのPathは このようなJSONを作っておいて、 これで希望通りのPathを持った空のIAM Roleが作成できます。 必要な権限を記述したインラインポリシーをアタッチして終わりです。IAM Role作成手順
空のIAM Roleを作る
/service-role/である必要があるようです。現状コンソールからはそのようなIAM Roleを作成することはできない(無条件で /になる)のでCLIを叩きましょう。{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Principal":{"Service":"lambda.amazonaws.com"},"Action":"sts:AssumeRole"}]}
aws iam create-role --role-name cloudwatch-synthetics --path /service-role/ --assume-role-policy-document file://policy.json
IAM Policyをアタッチする
{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Action":["s3:PutObject","s3:GetBucketLocation"],"Resource":["arn:aws:s3:::YOUR-BUCKET-NAME/*"]},{"Effect":"Allow","Action":["logs:CreateLogStream","logs:PutLogEvents","logs:CreateLogGroup"],"Resource":["arn:aws:logs:ap-northeast-1:999999999999:log-group:/aws/lambda/*"]},{"Effect":"Allow","Action":["s3:ListAllMyBuckets"],"Resource":["*"]},{"Effect":"Allow","Resource":"*","Action":"cloudwatch:PutMetricData","Condition":{"StringEquals":{"cloudwatch:namespace":"CloudWatchSynthetics"}}}]}
スクリプトの文法が良く分からんしテスト実行が遅い
CloudWatch Syntheticsの実体はAWS Lambda (Node.js)で、裏でHeadless ChromeをPuppeteer経由で動かしています。遅いのも当然ですしスクリーンショットに日本語が出てこないのも当然です(フォントを入れるにはLambdaの容量制限が厳しすぎます)。そこでローカルでコードを書いてから持って行くのが良さそうなのでその準備をします。なお今回Dockerは使っていませんのでよろしくお願いします。
ローカルでPuppeteerを動かす準備をする
新しめのNode.js をインストールする
n packageを使う方法が最もお手軽ですが、一時的に動かなかったという報告があったのでうまくやってください。なお2020/5/20時点においてCloudWatch SyntheticsはNode.js v10を利用しているそうです。そんなに複雑な文法を使わなければv12でもまあ問題はないでしょう。
依存モジュールをインストールする
公式の手順にある通り、必要なものを全部突っ込みます。勢いが大切です。
sudo apt install ca-certificates fonts-liberation gconf-service libappindicator1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 lsb-release wget xdg-utils
sudo yum install alsa-lib.x86_64 atk.x86_64 cups-libs.x86_64 GConf2.x86_64 gtk3.x86_64 ipa-gothic-fonts libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXrandr.x86_64 libXScrnSaver.x86_64 libXtst.x86_64 pango.x86_64 xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-fonts-cyrillic xorg-x11-fonts-misc xorg-x11-fonts-Type1 xorg-x11-utils
空のディレクトリを作って初期化する
mkdir hello-puppeteer;cd$_; npm init -yPuppeteerをインストールする
npm install--save puppeteer
サンプルコードを書いて実行してみる
公式のサンプルコードをちょっと変更して持ってきました。
constpuppeteer=require('puppeteer');(async()=>{constbrowser=awaitpuppeteer.launch();constpage=awaitbrowser.newPage();awaitpage.goto('https://www.google.com');awaitpage.screenshot({path:'example.png'});awaitbrowser.close();})();さっそく実行しましょう。
node index.js
うまく行けば同じディレクトリの中にGoogleのトップページのスクリーンショット、 example.pngという画像ファイルが生成されているはずです。
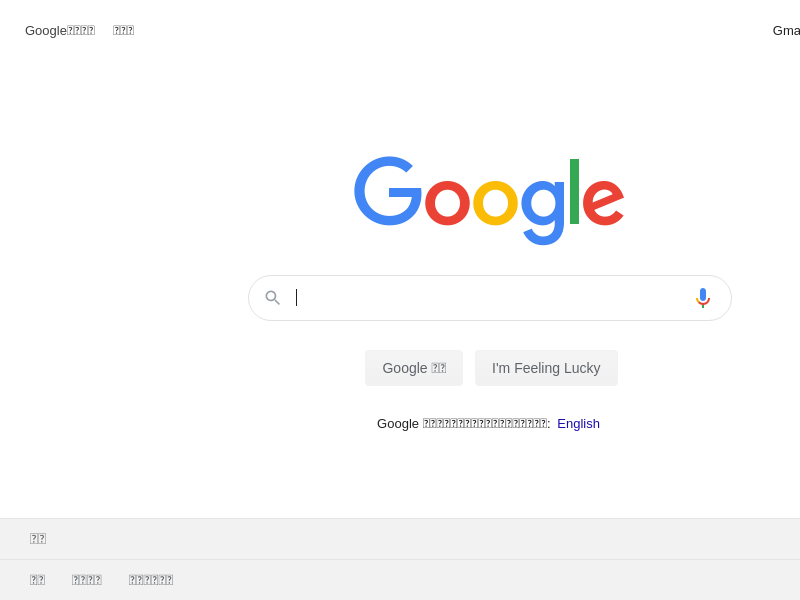
おめでとうございます! ここまでで最低限のコードは書けるようになりました!(フォントがないので日本語は全部文字「?」になってしまっています。どうせAWSに持って行くとこれは避けられないので諦めましょう)
CSS SelectorとXPath
単なる死活監視ならこれでオッケーですが、検索や検索結果検証を行うためにはHTML内の要素を探し出して取得する必要があります。そのために必要な武器がCSS Selectorです。XPathに慣れている人はXPathでもいいです。どちらもHTMLのツリー構造をたどり、必要な要素――文字を入力したりボタンを押したり文字列を探し出したり――を探し出すのに使うことができます。こちらの記事がとても参考になりました。
puppeteerでの要素の取得方法 - Qiita (@go_sagawaさん)
XPathの文法はそれなりに複雑ですし、スクレイピングを柔軟に1行うためにはある程度きちんと書く必要がありますが、対象のWebサイトの構造が固定であるという前提があれば何も覚える必要はありません。Chromeで対象の要素を右クリックし、「要素を調査」で開発者ツールを開き、対象の要素がハイライトされていることを確認したら、そこでさらに右クリックして「Copy XPath」をクリックするだけです。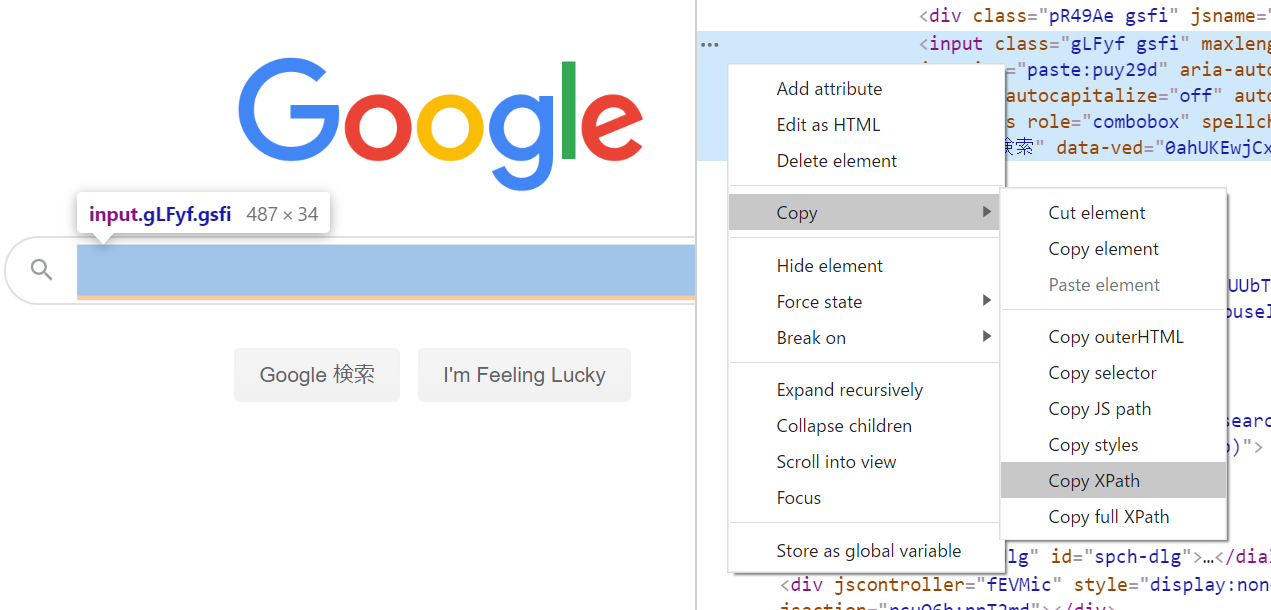
コードを書いてみよう
XPath版
必要なXPathが入手できたので実際にコードを書いてみます。
constpuppeteer=require('puppeteer');(async()=>{constbrowser=awaitpuppeteer.launch();constpage=awaitbrowser.newPage();constsearchTextboxXPath='//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input';constfirstSearchResultXPath='//*[@id="rso"]/div[1]/div/div/div[1]/a/h3';awaitpage.goto("https://www.google.com");// 検索テキストボックスが見つかるまで待つ(タイムアウト3秒)awaitpage.waitForXPath(searchTextboxXPath,{timeout:3000});// テキストボックスを取得(XPathでは配列で結果が返るので最初の要素を取る)consttextbox=(awaitpage.$x(searchTextboxXPath))[0];// フォーカスを合わせるために1回クリックしておくawaittextbox.click();// ディレイを入れつつキー入力awaitpage.keyboard.type("猫 wikipedia",{delay:100});// エンターキーを押す。検索画面に移動するはずawaitpage.keyboard.press('Enter');// 見出しが出てくるまで待つ(タイムアウト3秒)awaitpage.waitForXPath(firstSearchResultXPath,{timeout:3000});// 見出しを取得(これも配列なので最初の1個を取る)constfirstSearchResult=(awaitpage.$x(firstSearchResultXPath))[0];// 文字列を取得するためのやり方constresult=await(awaitfirstSearchResult.getProperty('textContent')).jsonValue();awaitpage.screenshot({path:"example.png"});if(result!=="ネコ - Wikipedia"){thrownewError("Wikipedia dokka itta nya!!!");}awaitbrowser.close();})();CSS Selector版
ほとんど変わりませんがCSS Selector版も書いておきます。
constpuppeteer=require('puppeteer');(async()=>{constbrowser=awaitpuppeteer.launch();constpage=awaitbrowser.newPage();constsearchTextboxSelector='#tsf input[type="text"]';constfirstSearchResultSelector='#rso div.r > a > h3';awaitpage.goto("https://www.google.com");// 検索テキストボックスが見つかるまで待つ(タイムアウト3秒)awaitpage.waitFor(searchTextboxSelector,{timeout:3000});// テキストボックスを取得consttextbox=(awaitpage.$(searchTextboxSelector));// フォーカスを合わせるために1回クリックしておくawaittextbox.click();// ディレイを入れつつキー入力awaitpage.keyboard.type("猫 wikipedia",{delay:100});// エンターキーを押す。検索画面に移動するはずawaitpage.keyboard.press('Enter');// 見出しが出てくるまで待つ(タイムアウト3秒)awaitpage.waitFor(firstSearchResultSelector,{timeout:3000});// 見出しを取得constfirstSearchResult=(awaitpage.$(firstSearchResultSelector));// 文字列を取得するためのやり方constresult=await(awaitfirstSearchResult.getProperty('textContent')).jsonValue();// スクショを取っておくawaitpage.screenshot({path:"example.png"});// 求める値になっているかチェックif(result!=="ネコ - Wikipedia"){thrownewError("Wikipedia dokka itta nya!!!");}awaitbrowser.close();})();CloudWatch Syntheticsにコピペしよう
「ハートビートのモニタリング」を選ぶとひな形のコードが出てきます。
varsynthetics=require('Synthetics');constlog=require('SyntheticsLogger');constpageLoadBlueprint=asyncfunction(){// INSERT URL hereconstURL="https://google.com";letpage=awaitsynthetics.getPage();// 中略};exports.handler=async()=>{returnawaitpageLoadBlueprint();};pageオブジェクトは既に与えられているので、セレクタ宣言部分から await browser.close()手前までをコピペすればいいですね。またスクリーンショットはローカルに保存することはできないので
awaitsynthetics.takeScreenshot("hoge");awaitsynthetics.takeScreenshot("fuga","piyo");などとSyntheticsの提供するメソッドを使う必要があります。(引数に与えた文字列がハイフンで結合されてファイル名になり、png形式で保存されます)
CloudWatchのアラームを作成する
CloudWatch Syntheticsからも直接アラームは作成できますが、アラームの名前が勝手に決まってしまうためちょっとイケていません。アラームを作ったらChatbot経由でSlack通知をするなどしたら監視は完成です。
Chromeが生成するXPathをそのまま使うとちょっと要素が増減したりしただけで動かなくなったりします ↩