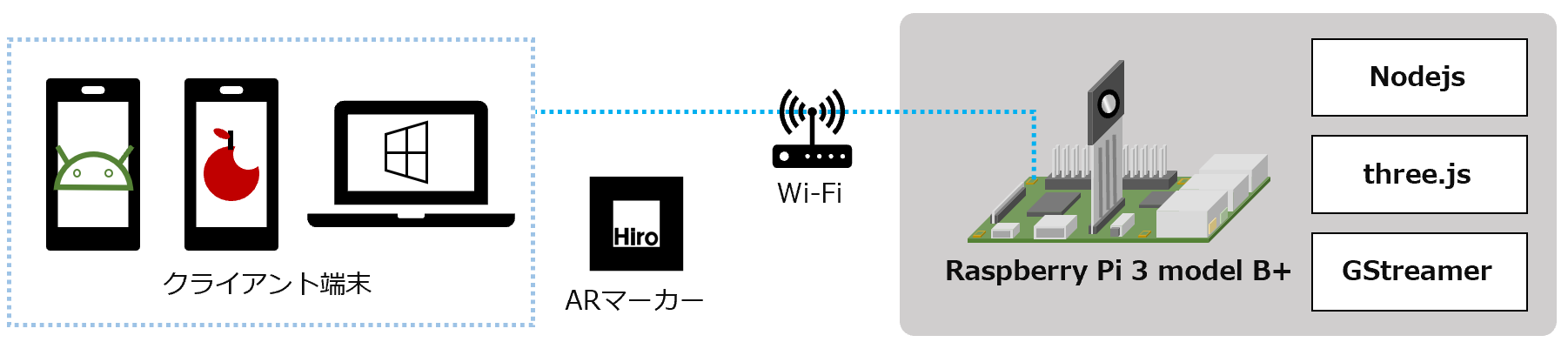
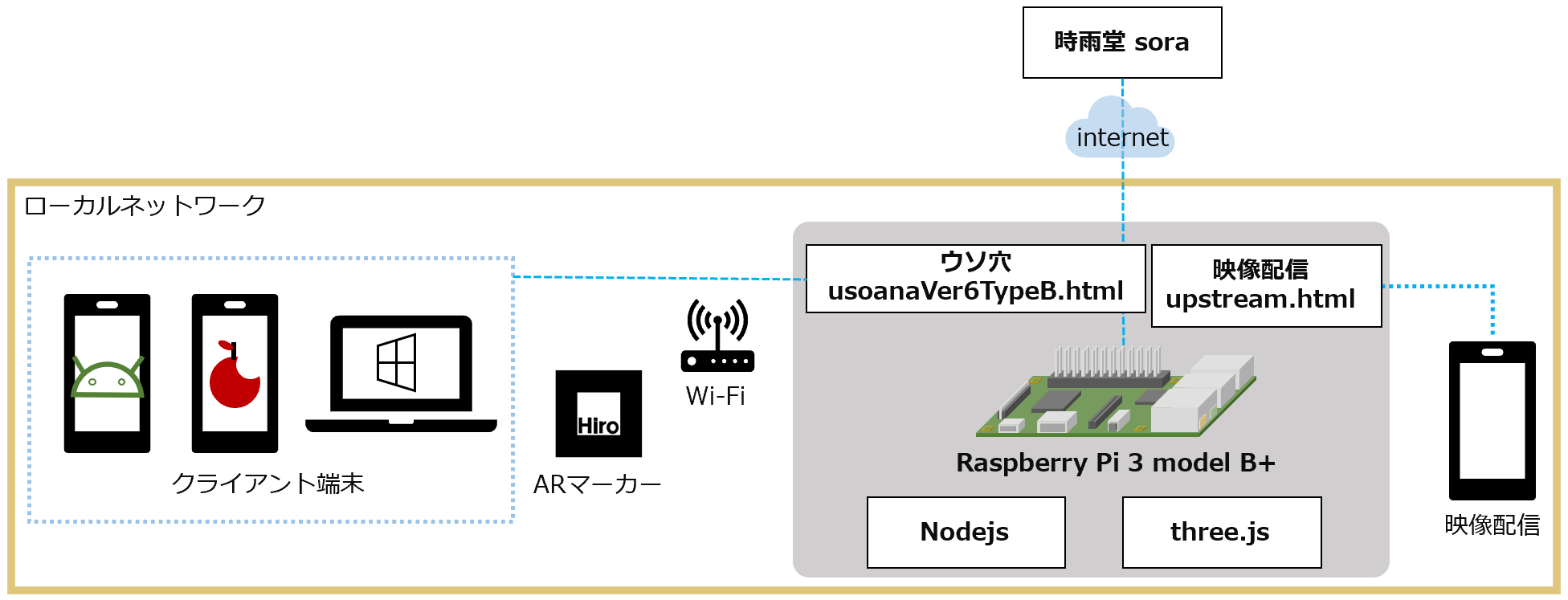
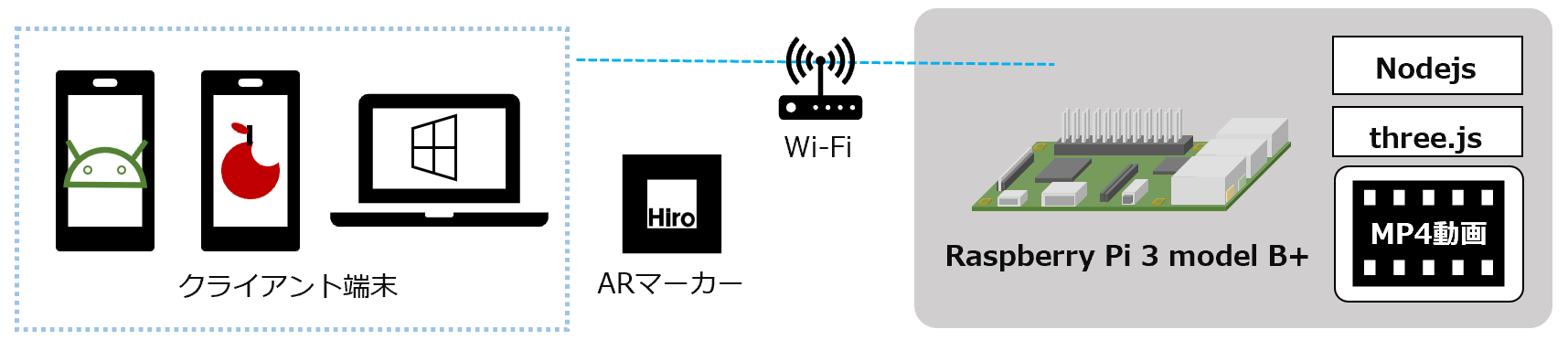
SaaSのサービスをAPI同士で繋いで、業務改善アプリ的なものをつくるのが近年の趣味な筆者です。こんにちは。
マネーフォワードクラウド請求書 is 何?
マネーフォワードクラウドは、freeeと人気を二分する、中小企業やフリーランス向けのSaaS会計システムです。筆者は会社勤務の傍ら副業もしてますので、マネーフォワードクラウド確定申告というのを使って、毎年確定申告をしています。
また、関連サービスとしてマネーフォワードクラウド請求書(以下MFクラウド請求書)というサービスもあり、これを使って見積書と請求書を発行しています。
本稿とは別の余談になりますが、なかなかよく出来たサービスですので、請求書発行のサービスを探しておられる方は一度トライアルされてみてはいかがでしょうか。
Exment is 何?
Exmentは、OSSのWeb DBシステムです。SaaSではありませんが、筆者はLightSail + Dockerというクラウド環境で試験運用しています。
詳しくは下記記事をご参照ください。
また、詳しくは開発者の方の記事も参考になると思います。
APIで繋ぎこむ
MFクラウド請求書もExmentもAPIが用意されています。となると繋ぎこんでみたくなるのが人情というもの。
MFクラウド請求書はあくまで請求書発行のためのサービスなので、顧客マスタの概念はあっても、そこに対してのSFAやCRM的な機能はありません。
そこで、APIを使って、汎用的なDBシステムであるExmentにデータをコピーし、Exment上で色々やってみたいと思います。
この記事で実現できること
おおまかには以下です。
- 顧客ごとの売上額がわかる
- 顧客ごとの見込み額がわかる
- 案件ごとの見込み確度がわかる
これらの機能はMFクラウド請求書だけでは数値化・視覚化することができません。
セールスや経営の現場では、これらの情報が日々重要であり、セールス担当者は案件ごと、顧客ごとにこれらの情報を元に効率よく行動することができるようになります。それがSFAやCRMに求められる機能です。
SalesforceやkintoneといったSaaSを契約している企業であれば、それらでやってしまえばいいのでしょうけど、それらを契約できない規模の中小企業や私のような副業ワーカーであれば、Google App Scriptや、今回のExmentでやる、というのが現実的な方向性になると思います。
MF請求書のAPI仕様
MFクラウド請求書は、アクセストークンが必要で、リフレッシュトークンとともに発行される仕組みです。アクセストークン発行の仕組みは、下記記事をご覧ください。
APIドキュメントはこちらです。
ExmentのAPI仕様
ExmentのAPIは、3つの認証方式があります。今回は、API Key方式で行きたいと思います。MFクラウド請求書APIと同じく、アクセストークンとリフレッシュトークンが発行される方式です。
詳しくは下記記事を参考にしてください。
ExmentのAPIドキュメントはこちらです。
実装してみる
さて、いよいよ実装です。まずは、Exment側でカスタムテーブルを作ります。Salesforceでいうところのオブジェクト、kintoneで言うところのアプリ、そしてRDBMSで言うところの、テーブルに相当します。
「顧客リスト」カスタムテーブルの作成
カスタムテーブル作成の実際は、下記記事が詳しいので、ぜひご参照ください。
以下は、私が作成した「顧客リスト」のカスタム列設定です。RDBMSでいうところの、スキーマに相当します。カッコ内は、列種類(Exmentの用語、RDBMSでいうところの「型」に相当)
以上です。そっけないかもしれませんが、今回は顧客データベースをつくるのではなく、顧客ごとに売上や案件を管理したいだけなので、まずはこれだけにしておきます。
なお、idやcreated_atなどの列は自動的に追加されます。
「案件一覧」カスタムテーブルの作成
続いて、案件のカスタムテーブルを作成します。作成したカスタム列は、以下の通りです。この段階で、MFクラウド請求書API側のレスポンスのどのデータをどの列に突っ込みたいかを考えておきます。今回は、営業的な面で必要なものだけに絞りました。
- 案件名(一行テキスト)※
- 顧客名(選択肢(他のテーブルの値一覧から選択))※
- 金額(税込)(通貨)※
- 金額(税抜)(通貨)※
- 確度(選択肢(値・見出しを登録))※
- 除外(YES/NO)
- 引き合い日(日付)
- 見積作成日(日付と時刻)※
- 見積書更新日(日付と時刻)※
- 受注日(日付)
※印をつけた項目は、MFクラウド請求書側からのデータを受け付ける列になります。金額に税込と税別があるのも、MFクラウド請求書側がそのプロパティを持っているからですね。
また、確度の項目は、以下のように設定しました。(RDBMSでいうところのenum型ですね)
- 1,アイデアレベル
- 2,検討中
- 3,見積発行
- 4,商談中
- 5,意思決定直前
- 6,受注
- 7,失注
- 8,保留
1から6までは、受注確度です。営業用語でいうところの「顧客の温度感」ってヤツです。
アクセストークンを取得しておく
先程リンクしたMFクラウド請求書APIの記事を読んで、アクセストークンを取得します。
実際にはPostmanを使用して取得しました。
本当はプログラム化しておいたほうが良いのですが…
続いて、Exmentのアクセストークン取得です。こちらはプログラム化しました。普段筆者はJavaScriptに慣れ親しんでいるので、今回はNode.jsで書いています。ローカルで運用する前提です。
auth_exment.js
constaxios=require('axios')constfs=require('fs')constmoment=require('moment')constisExistFile=(file)=>{try{fs.statSync(file);returntrue}catch(err){if(err.code==='ENOENT')returnfalse}}constgetTokens=async(refresh_token)=>{letbody=''if(refresh_token){body={grant_type:'refresh_token',client_id:'df013b70-f1aa-11ea-8af3-c94ebdad7ad4',client_secret:'PSXXuKY8R3MrllA8EFSqPYtX3o3Oj7RP8s1cQBy1',refresh_token:refresh_token}}else{body={grant_type:'api_key',client_id:'df013b70-f1aa-11ea-8af3-c94ebdad7ad4',client_secret:'PSXXuKY8R3MrllA8EFSqPYtX3o3Oj7RP8s1cQBy1',api_key:'key_7B3faSNwMcU4MkJv3BZ8hF9LFHS7uQ',scope:'me value_read value_write'}}awaitaxios.post('https://db.uplift.company/oauth/token',body,{headers:{'Content-Type':'application/json'}}).then(res=>{constat=res.data.access_tokenconstrt=res.data.refresh_tokenconstexpires=res.data.expires_inconstexpireDay=moment().add(expires,'s').format()constdata={access_token:at,refresh_token:rt,expires_in:expireDay}fs.writeFileSync('./exment_tokens.txt',JSON.stringify(data))return{tokens:data}}).catch(err=>{console.log(err)})};(async()=>{lettokens={}if(isExistFile('tokens.txt')){// 既にトークンが存在するときtokens=JSON.parse(awaitfs.readFileSync('exment_tokens.txt'))// トークンが期限切れの時if(moment().isAfter(tokens.expireDay)){tokens={}getTokens(tokens.refresh_token)// リフレッシュトークンを使って、再取得tokens=JSON.parse(awaitfs.readFileSync('exment_tokens.txt'))}}else{// トークンが存在しない時getTokens()tokens=JSON.parse(awaitfs.readFileSync('exment_tokens.txt'))}console.log(tokens)returntokens})()やってることは単純で、トークンの情報が書かれたテキストファイルが存在しなければ、初回トークン作成のPOSTをaxiosで投げます。そして取得したトークンの情報をローカルにテキストファイルで保存します。
顧客リスト取得とExmentに突っ込むプログラムを書いてみる
引き続き、顧客リスト取得のプログラムです。これもローカルで1回実行することが前提です。ホスティングして定期的に回すことは今のところ前提としていません(本当はそこまでやりたいですけど)
get-clients.js
constaxios=require('axios')constfs=require('fs');(async()=>{constendpoint='https://invoice.moneyforward.com/'constquery='api/v2/partners'awaitaxios.get(endpoint+query,{headers:{'Accept':"application/json",'Authorization':'Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'}}).then(async(res)=>{console.log(res)letitems=[]res.data.data.forEach(item=>{items.push({parent_type:'',value:{name:item.attributes.name}})})consttokens=JSON.parse(awaitfs.readFileSync('./exment_tokens.txt'))constexmentEndpoint='https://db.uplift.company/api/data/clients'awaitaxios.post(exmentEndpoint,{data:items},{headers:{'Authorization':'Bearer '+tokens.access_token}}).then(res=>{console.log(res)}).catch(err=>{console.log(err)})}).catch(err=>{console.log(err.errors)})})()MFクラウド請求書APIのアクセストークンがベタ書きです。いけませんね。良い子は真似しちゃダメです。dotenvなどで適切に処理しましょう。
それ以外の処理についてですが、
- 空の配列itemsにMFクラウド請求書APIをaxiosのGETで叩いた結果を収める
- itemsをペイロードに詰め、axiosのPOSTでExmentのAPIに投げる
というのがおおまかな流れです。itemsに突っ込む時は、ExmentのAPIドキュメントにあるカスタムデータ新規作成の記事を読んで、
![2020-09-10_13h54_04.png]()
上図は、突っ込んでみた結果です。うまく行きました。
案件(見積書)データを取得とExmentに突っ込むプログラムを書く。
引き続き、Node.jsです。
set-project.js
constaxios=require('axios')constfs=require('fs')const_=require('lodash')constmoment=require('moment');(async()=>{constendpoint='https://invoice.moneyforward.com/'constquery='/api/v2/quotes'awaitaxios.get(endpoint+query,{headers:{'Authorization':'Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'}}).then(async(res)=>{// console.log(res) // クライアント名とIDの紐付けデータ作成consttokens=JSON.parse(awaitfs.readFileSync('./exment_tokens.txt'))constexmentClietnsEndopoint='https://db.uplift.company/api/data/clients'letclients=[]awaitaxios.get(exmentClietnsEndopoint,{headers:{'Authorization':'Bearer '+tokens.access_token}}).then(res=>{res.data.data.forEach(item=>{clients.push({id:item.id,name:item.value.name})})})letitems=[]conststatus=async(item)=>{if(item.attributes.order_status==='default'){return3// 見積作成フラグ}elseif(item.attributes.order_status==='received'){return6// 受注フラグ}elseif(item.attributes.order_status==='failure'){return7// 失注フラグ}}constgetId=async(item)=>{constclient=_.find(clients,{name:item.attributes.partner_name})if(client){returnclient.id}else{return8// 取引停止}}constexclude=async(cond)=>{if(cond===8){returntrue}else{returnfalse}}for(leti=0;i<res.data.data.length;i++){letpdf=''awaitaxios.get(res.data.data[i].attributes.pdf_url,{responseType:'arraybuffer',headers:{'Authorization':'Bearer bbbf071b178fb29f1be08d41f3aad341ba599433f58d795d937266fd8d11dfda'}}).then(res=>{console.log('get pdf succeeded')pdf=newBuffer.from(res.data,'binary').toString('base64')}).catch(err=>console.log(err))constpayload={value:{name:res.data.data[i].attributes.title,client:awaitgetId(res.data.data[i]),amount:Math.floor(Number(res.data.data[i].attributes.total_price)),sub_amount:Math.floor(Number(res.data.data[i].attributes.subtotal)),reliability:awaitstatus(res.data.data[i]),exclude:awaitexclude(awaitgetId(res.data.data[i])),estimate_created_at:moment(res.data.data[i].attributes.created_at).format('YYYY-MM-DD HH:mm:ss'),estimate_updated_at:moment(res.data.data[i].attributes.updated_at).format('YYYY-MM-DD HH:mm:ss'),}}constexmentEndpoint='https://db.uplift.company/api/data/projects'awaitaxios.post(exmentEndpoint,{data:[payload]},{headers:{'Authorization':'Bearer '+tokens.access_token}}).then(async(res)=>{// console.log(res.data[0].id)awaitaxios.post('https://db.uplift.company/api/document/projects'+'/'+res.data[0].id,{name:JSON.parse(res.config.data).data[0].value.name+'_見積書.pdf',base64:pdf},{headers:{'Authorization':'Bearer '+tokens.access_token}}).then(res=>{console.log(res)}).catch(err=>{console.log(err.response.data.errors)})}).catch(err=>{console.log(err)})}}).catch(err=>{console.log(err)})})()今回はちょっとばかり複雑なのと、axiosのコールバックがネストしまくってて、これもあまり良くありません。まあ、ワンオフ1回きりのコードなので、大目に見てください…
さて、各部の説明です。
set-project.js
constendpoint='https://invoice.moneyforward.com/'constquery='/api/v2/quotes'awaitaxios.get(endpoint+query,{headers:{'Authorization':'Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'}}).then(async(res)=>{// console.log(res) // クライアント名とIDの紐付けデータ作成consttokens=JSON.parse(awaitfs.readFileSync('./exment_tokens.txt'))constexmentClietnsEndopoint='https://db.uplift.company/api/data/clients'letclients=[]awaitaxios.get(exmentClietnsEndopoint,{headers:{'Authorization':'Bearer '+tokens.access_token}}).then(res=>{res.data.data.forEach(item=>{clients.push({id:item.id,name:item.value.name})})})まず、axiosのGETでクライアント名一覧をMFクラウド請求書側から取得しています。まあ、Exment側から取っています… というか、これ、今気づいたんですが、Exmentに既に顧客テーブル作ったんだから、そっちから取得しても良かったんじゃね? って思いました… 次回からそうしよ。
次に初回axiosのコールバックで、またまたaxiosのGETでExmentのAPIを叩き、Exmentの顧客id(先程の挿入時に自動採番されている)を取得します。
最後に、両者を紐付けて、空の配列clientsにオブジェクトで突っ込みforEachで回します。
set-project.js
letitems=[]conststatus=async(item)=>{if(item.attributes.order_status==='default'){return3// 見積作成フラグ}elseif(item.attributes.order_status==='received'){return6// 受注フラグ}elseif(item.attributes.order_status==='failure'){return7// 失注フラグ}}constgetId=async(item)=>{constclient=_.find(clients,{name:item.attributes.partner_name})if(client){returnclient.id}else{return8// 取引停止}}constexclude=async(cond)=>{if(cond===8){returntrue}else{returnfalse}}let items = []でからの配列を作成しています。
status関数は、それぞれの案件がどういう状態にあるかを定義する関数です。見積書があるということは、Exment側の「確度」項目では「3の見積作成」に相当するので、3を返すように。受注したものは6を、失注は7を返すようにしました。
getId関数は、顧客名から、Exmentの顧客idを取得できるようにするものです。lodashのfindメソッドを使って紐付けしています。
clientのid8番は、取引停止という特殊なクライアントです。MFクラウド請求書側で顧客データを削除してしまった場合は、顧客名が空欄になるので、Exment側で取引停止というクライアントを作成して対応させています。
exclude関数は、そもそも取引停止になっている案件の見積書は、除外しておきたいよね、という目的で作成しました。Exment側の「除外」列に相当します。クライアントid8番(つまり、取引停止)の場合は、除外列にtrueをセットします。
set-clients.js
for(leti=0;i<res.data.data.length;i++){letpdf=''awaitaxios.get(res.data.data[i].attributes.pdf_url,{responseType:'arraybuffer',headers:{'Authorization':'Bearer bbbf071b178fb29f1be08d41f3aad341ba599433f58d795d937266fd8d11dfda'}}).then(res=>{console.log('get pdf succeeded')pdf=newBuffer.from(res.data,'binary').toString('base64')}).catch(err=>console.log(err))constpayload={value:{name:res.data.data[i].attributes.title,client:awaitgetId(res.data.data[i]),amount:Math.floor(Number(res.data.data[i].attributes.total_price)),sub_amount:Math.floor(Number(res.data.data[i].attributes.subtotal)),reliability:awaitstatus(res.data.data[i]),exclude:awaitexclude(awaitgetId(res.data.data[i])),estimate_created_at:moment(res.data.data[i].attributes.created_at).format('YYYY-MM-DD HH:mm:ss'),estimate_updated_at:moment(res.data.data[i].attributes.updated_at).format('YYYY-MM-DD HH:mm:ss'),}}constexmentEndpoint='https://db.uplift.company/api/data/projects'awaitaxios.post(exmentEndpoint,{data:[payload]},{headers:{'Authorization':'Bearer '+tokens.access_token}}).then(async(res)=>{// console.log(res.data[0].id)awaitaxios.post('https://db.uplift.company/api/document/projects'+'/'+res.data[0].id,{name:JSON.parse(res.config.data).data[0].value.name+'_見積書.pdf',base64:pdf},{headers:{'Authorization':'Bearer '+tokens.access_token}}).then(res=>{console.log(res)}).catch(err=>{console.log(err.response.data.errors)})}).catch(err=>{console.log(err)})}いよいよ回していきます。ちょっとこの下りが複雑で冗長なのですが、大まかな流れとしては以下です。
- 見積書PDFの取得 from MFクラウド請求書API
- PDFデータをbase64エンコードして、空の変数に突っ込む
- ペイロードに突っ込むデータを作る。金額は小数点でMFクラウド請求書APIから返ってくるので、Math.floorで丸めておく。
- ExmentのAPIにaxiosのPOSTで1件のデータを突っ込む
- そのレスポンスで返ってきた案件idを利用し、コールバックでもう一度axiosのPOSTで、今度は個別の案件に対してPDFを突っ込む
という処理をしています。
ExmentのAPI側は、複数案件をオブジェクトに収めて投げても受け付けてくれるのですが、これだとまとめて見積書PDFを収めることができません。そこで、1案件ごとに各フィールドを埋めるペイロードを用意し、POSTするようにし、axiosのコールバックとレスポンスで返ってくるid番号を利用してPDFだけあとから突っ込むということを実現できました。(いやー、コールバックとレスポンスって、こういうことのために使うんですねぇ。初めてこんなことしたので、勉強になりました)
なお、PDFを添付ファイルに添付する必要がなければ、複数案件まとめてAPIに投げちゃってもいいかな、と思います。その方が早いしリクエストも1回で済みますしね。
なお、PDF取得の処理にそれなりに時間がかかるので、Exment側(というかLaravel)のAPIコール上限には達しませんでしたが、必要があればExment側のAPIコール上限を緩和する設定などを施してください。
さて、無事データが突っ込めました。下記のようになってるでしょうか
![2020-09-10_14h41_30.png]()
(実際にはこの画像、突っ込んだ後に編集しているので、厳密には異なる内容となるはずです)
Exment側でビューを作っていく
さて、ここまで来たらあとはNoCodeです。
Exmentにはビューという機能があります。デフォルトでは全件ビューというのになっていて、スプレッドシートのような外観をしています。
カスタムビューは、これらのデータを特定の条件に従ってフィルタリングしたり計算したりできる機能です。
フィルターだけなら全件ビューでもできるのですが、それを保存してユーザー間で共有できるところがビューの強みになります。
なお、計算ができるといっても簡易なものなので、複雑な処理をしたければ、APIからデータを取得して、処理するアプリケーションの開発をする必要があります。
さて、今回は以下のビューを作ってみます。
- 顧客別売上(今年)
- 顧客別売上(昨年)
- 見込み総額
- リードタイム
顧客別売上(今年)
案件情報画面に入り、右上にある「テーブル詳細設定」ボタンを押します。次に、出てきたモーダル内の「ビュー設定」
を押します。カスタムビュー設定という画面になるので、右上の「+新規」を押します。
またモーダルが出てくるので「集計ビュー新規作成」を押します。
「カスタムビュー設定 作成」という画面になるので、まずはビュー表示名のところを「顧客別売上(今年)」にします。
グループ列選択、集計列選択、データ表示条件は、以下のように設定しましょう。
![2020-09-10_14h54_04.png]()
グループ列選択
集計したい軸を選択します。今回は顧客ごとに金額を集計するので、「顧客名」を選択しています。
集計列選択
集計したい値を選択します。今回は顧客ごとの金額ですので、「金額(税込)」と「金額(税抜)」を選択しました。
データ表示条件
列の値を使って、集計する対象を選定します。フィルタリングですね。
なお、今更なんですが、案件情報の列について、そのもたせた意味についてちょっと説明です。
除外
副業というか、受託をやってると「ちょっと見積書だけほしいんだけど(発注するかどうかは怪しいけど)」みたいなケースがあります。実際には、クライアントが補助金や助成金ありきのサイト制作を考えていて、その申請書類として見積書がほしいということでした。
そういう案件は受注するといいのですが、結構な金額で実際には受注しないということも多いので、営業戦略的には邪魔なデータとなってしまいます。
そんな案件は、手動で除外したいので「除外」というフラグを持たせています。また、取引停止の見積書もこの設定にしたのは先述の通りです。
確度
ここでは、確度ステータスは受注したか否かの判定に使っています。
受注日
これも営業戦略的には非常に重要で、月や四半期の売上目標の判定に必要です。今回は「今年」という期間なので、受注日が今年の範疇に含まれるものを設定しています。
出来たビューを見てみる
![2020-09-10_15h08_21.png]()
こんな感じです。筆者は副業ということもあり、アクティブな取引先はそんなに多くないのですが、取引先の多い企業では、ここがずらずら~っと並んで、取引額の多い順番に並ぶということですね。
実際の営業現場では、取引先の金額が高い順番に、手厚い対応を取ることになると思います。
顧客別売上(昨年)
ということは、集計ビューを作った時に、データ表示条件で受注日を絞ったところを「去年」にすれば昨年の売上も出るわけですね。
一度作ったビューはコピーすることができるので、顧客別売上(今年)を複製して、最後の設定だけ変更してみましょう。
カスタムビュー設定画面の右端「操作」列の、2枚の紙が重なったアイコンをクリックすると、そのビューを複製することができます。
簡単ですね。
見込み総額
先程までは、売上、つまりこれまでの数値を可視化しました。営業的には「これから」の数値である「見込み総額」を算出したいと思います。
見込み総額ビューの設定は下記の通りです。
![2020-09-10_15h22_46.png]()
売上の時と考え方は同じで、フィルタリングする条件で、確度を受注以前状態の値に設定しています。
リードタイム
リードタイムとは、引き合いをもらってから、受注に至るまでの期間のことです。見積り金額が増えれば増えるほどリードタイムが伸びる傾向にあります(それだけ大きいプロジェクトなので、顧客の意思決定にも複数人が関わる)。リードタイムが短い価格低めの案件を大量に獲るか、長めの案件を獲るかの基準づくりや、リードタイムかかりすぎの案件を洗い出すための判断基準として重要です。
今回の例では、引き合い日と受注日が設定されている案件が対象となります。リードタイムでは、カレンダービューという機能を使います。設定は下図の通りです。
![2020-09-10_16h08_33.png]()
すると、こんな風にカレンダー表示してくれます。
![2020-09-10_16h09_38.png]()
ま、正直この見せ方はベストではないと思うんですが、感覚的にリードタイムを掴むには良いのかな、と思いました。もう少し正確に把握するためには、やはりmomentとかで日付計算をして「○○万円以上の案件で△日以上リードタイムかかってたらアラートをだす」みたいなアプリを開発すべきでしょう。
これはひとつ、簡易的なやりかたということで。
まとめ
見積書・請求書に特化したサービスであるMFクラウド請求書を、汎用WebDBであるExmentと連携させて、簡易的なSFA/CRMにしてみました。SFA/CRMと名乗るにはまだまだ機能が足りないのですが、取り敢えず
- どんぐらい稼げてるか
- 太客はどこか
- 案件獲得にどれくらいかかってるか
などは、これで洗い出せることになりました。
Google App Script + Googleスプレッドシートなどもいいですが、Exmentはカスタムビューの機能が強力だな、と思い今回は活用してみました。
Node.jsのくだりも、ただ今回インポートするだけの機能しかないので、今後は定期的に実行してMFクラウド請求書側のマスタとExment側のマスタが同期するような仕組みも作ってみたいと思います。
また、双方のAPIの仕組みもなんとなくわかっていただけたのではないでしょうか。双方ともに基本的なCRUDが出来るので、やりようによってはもっと高度な分析や日々の運用もこなせると思います。
これを機会に、MFクラウド請求書やExmentのユーザーが増えてくれると嬉しいです。