↧
Firebase CloudFunctions x TypeScript をデバッグしながらHotDeploy
↧
Node.jsでYYYYMMDDの文字列を出力する
概要
Node.jsを使って現在日時からYYYYMMDDの文字列を出力します。
2020/2/3なら20200203となります。
少し工夫しないと202023とかになってしまいます。
実際のコード
constcreateYYYYMMDD=()=>{consttoday=newDate();constmonthMM=('0'+(today.getMonth()+1)).slice(-2);constdayDD=('0'+(today.getDay()+1)).slice(-2);returntoday.getFullYear().string()+monthMM+dayDD;};console.log(createYYYYMMDD);// 20200203ポイント
getMonth(), getDay()で得られる値は、現在の月(日)から1引いた値となります。
そのため1を足して(today.getMonth() + 1)います。
さらに'0' +として、先頭に0を付けた文字列に変換して、.slice(-2)で必ず2文字になるようにします。
↧
↧
Node.jsでhtmlのlinkタグなどから外部ファイルを読み込めないときの解決法
Node.jsでJavaScript入門書のサンプルコードを実行したが、htmlのlinkタグとscriptタグでcssとJavaScriptが読み込まれなかった。
なお学習目的のため以下の条件を設けている
- Expressなどのフレームワークは使わない
- サンプルのディレクトリ構造は変えない
サンプルコード
入門書のコードをそのままここに書くわけにはいかないので、自作のサンプルコードを記しておく。
ディレクトリ構成図
.
├── common
│ ├── jquery-3.4.1.min.js
│ └── style.css
└── samples
├── sample1
│ ├── index.html
│ └── script.js
└── sample2
ピンク色の「うんこ」を表示するサンプルコード
index.html
<!DOCTYPE html><htmllang="ja"><head><metacharset="UTF-8"><metaname="viewport"content="width=device-width, initial-scale=1.0"><metahttp-equiv="X-UA-Compatible"content="ie=edge"><title>sample1</title><linkhref="../../common/style.css"rel="stylesheet"></head><body><h1>うんこ</h1><script src="../../common/jquery-3.4.1.min.js"></script><script src="./script.js"></script></body></html>style.css
h1{font-size:60px;color:deeppink;}cssを読み込めれば同じ方法でJavaScriptも読み込めるはずなのでJavaScriptは割愛。
Node.jsで実行してみる
上記のサンプルコードをNode.jsで実行するためsample1/app.jsを作成
app.js
consthttp=require('http');constfs=require('fs');constindexHtml=fs.readFileSync('./index.html')constserver=http.createServer((req,res)=>{res.writeHead(200,{'Content-Type':'text/html'});res.write(indexHtml);res.end();});constport=8000;server.listen(port,()=>{console.info(`Listening on ${port}`);});$ node app.jsで実行しhttp://localhost:8000にアクセスすると
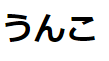
黒い。cssを読み込んでない。
考察
console.log(req.url)を追記
app.js
constserver=http.createServer((req,res)=>{console.log(req.url)res.writeHead(200,{'Content-Type':'text/html'});res.write(indexHtml);res.end();});
再度$ node app.jsで実行しhttp://localhost:8000にアクセス後コンソールを見てみると
/
/common/style.css
/common/jquery-3.4.1.min.js
/script.js
/favicon.ico
http://localhost:8000/common/style.cssなどにリクエストしてしている
http://localhost:8000/common/style.cssにアクセスしてみると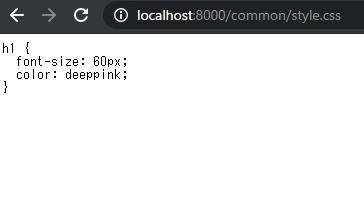
http://localhost:8000へのリクエストに対しindex.htmlをレスポンスとして返したのと同様に
http://localhost:8000/common/style.cssへのリクエストに対してレスポンスとしてsyle.cssを返すようにルーティングしてあげればよさそう。
解決方法
app.js
consthttp=require('http');constfs=require('fs');constindexHtml=fs.readFileSync('./index.html')conststyleCss=fs.readFileSync('../../common/style.css')constserver=http.createServer((req,res)=>{switch(req.url){case'/':res.writeHead(200,{'Content-Type':'text/html'});res.write(indexHtml);res.end();break;case'/common/style.css':res.writeHead(200,{'Content-Type':'text/css'});res.write(styleCss);res.end();break;default:break;}});constport=8000;server.listen(port,()=>{console.info(`Listening on ${port}`);}); $ node app.jsで実行しhttp://localhost:8000にアクセスすると

成功。同じ要領でJavaScriptも読み込める。
↧
Node.jsで常時フォルダを監視してS3へファイルをアップロードする
概要
あるフォルダに不定期にCSVファイルが作成されるので、そのCSVファイルをS3にアップロードするプログラムをNode.jsで作成します。
処理に失敗するとAWS SESを使って、管理者へメールを配信します。
loggerも使って何が起こったかを追えるようにします。
全コードはこちら
フロー
起動時に監視フォルダとローカルの保存フォルダが存在するかチェック
initial_check.js
constfs=require("fs");constfsPromises=fs.promises;constinitialCheck=async(WATCHING_DIR,DEST_DIR)=>{try{awaitfsPromises.access(WATCHING_DIR,fs.constants.R_OK|fs.constants.W_OK);awaitfsPromises.access(DEST_DIR,fs.constants.R_OK|fs.constants.W_OK);}catch(error){thrownewError("監視/管理フォルダへアクセスできない");}};module.exports=initialCheck;指定のフォルダが存在しなければ、プログラムは終了。その際にAWS SESから管理者へメールが配信されるようにしてあります。
chokidarでwatcherを起動して正常動作をチェック
watcherの設定
watcher.js
constchokidar=require("chokidar");// フォルダ監視用constWATCHING_DIR=require("./config.json").WATCHING_DIR;// Initialize watcher.constwatcher=chokidar.watch(WATCHING_DIR,{ignored:/[\/\\]\./,persistent:true,usePolling:true,interval:10000});module.exports=watcher;watcherの動作確認
monitoring.js
constwatcher=require("./watcher");// フォルダ監視用watcher.on("ready",async()=>{awaitlogger.info("Initial scan complete. Ready for changes");constwatchedPaths=watcher.getWatched();awaitlogger.info("watchedPaths :",watchedPaths);});監視フォルダにファイルが追加されたときの動作を設定
monitoring.js
// ファイルの追加を検知watcher.on("add",asyncfilePath=>{awaitlogger.info("add file: ",filePath);try{awaitbucketExistCheck();awaitlogger.info("Bucket Existed.");awaitfileCopyUploadDelete(filePath);}catch(error){awaiterrorState(error);}});S3のバケットが存在することを確認してから追加されたファイルをS3へアップロードします。
watcherがエラーとなった場合
monitoring.js
watcher.on("error",asyncerror=>{awaiterrorState(error);awaitwatcher.close().then(()=>logger.info("Watcher closed: watcher on error"));});S3バケットが存在するかをチェック
monitoring.js
constbucketExistCheck=async()=>{try{awaits3.headBucket({Bucket:BUCKET}).promise();}catch(error){thrownewError("S3 Bucket not exist!");}};追加されたファイルを処理する流れ
- ローカルで保存するためフォルダに
YYYYMMの名前でフォルダを作成 - そのフォルダに追加されたファイルをコピー
- 追加されたファイルをS3へアップロードするためのパラメーターを作成
- S3へアップロード
- 監視フォルダから追加されたファイルを削除
monitoring.js
constfileCopyUploadDelete=asyncfilePath=>{constfilenameParse=path.parse(filePath);// copyする前にYYYYMMのフォルダが存在するか確認して、存在しなければフォルダ作成するconstsendPathThisMonthDir=awaitmkdirThisMonth();constdestFilePath=path.join(sendPathThisMonthDir,filenameParse.base);awaitfsPromises.copyFile(filePath,destFilePath,COPYFILE_EXCL);awaitlogger.info("File copy success!",filePath,destFilePath);// コピー失敗した場合は? => 'EEXIST: file already exists, copyfile'のエラーメッセージthrow// COPYFILE_EXCLを指定しているためコピー先に同名ファイルがあった場合は上記エラー// renameメソッドでもファイル移動が可能だが、移動先に同名ファイルが存在する場合に上書きとなってしまうため利用せずconstuploadParams=awaitcreateUploadParams(filePath);awaitlogger.info("File Read Success",filePath);constdata=awaits3.putObject(uploadParams).promise();awaitlogger.info("Upload Success",data);awaitfsPromises.unlink(filePath);awaitlogger.info("File delete Success!",filePath);};YYYYMMのフォルダが存在しなければ作成する↓
monitoring.js
constmkdirThisMonth=async()=>{try{consttoday=newDate();constmonthMM=("0"+(today.getMonth()+1)).slice(-2);constyyyymm=today.getFullYear().toString()+monthMM;constdirPath=path.join(DEST_DIR,yyyymm);awaitfsPromises.mkdir(dirPath);logger.info("Make Directory",dirPath);returndirPath;}catch(error){if(error.code==="EEXIST"){logger.warn(error.message);returnerror.path;}thrownewError(error);}};S3へアップロードするためのパラメーターを作成↓
ファイルはcsvからjsonへ変換。なんとなくファイル名にランダム文字列を追加。ContentMD5キーを指定して正しくアップロードされたかをチェック
monitoring.js
constcreateUploadParams=asyncfilePath=>{try{constbody=awaitorderCsvToJson(filePath);// ファイルの中身をjson形式へ変換constmd5hash=crypto.createHash("md5");constmd5sum=md5hash.update(body).digest("base64");constrandomString=crypto.randomBytes(8).toString("hex");// ファイル名が重複しないようにするconstfilenameParse=path.parse(filePath);constkey=filenameParse.name+"_"+randomString+".json";return{Bucket:BUCKET,Key:key,Body:body,ContentMD5:md5sum};}catch(error){thrownewError(error);}};エラーが発生した場合はSESでメール配信
monitoring.js
consterrorState=asyncerror=>{awaitlogger.error(error.message);console.error(error);// 管理者へメール配信constsesParams=createSESParams(error);awaitsesSendMail(sesParams).then(res=>{logger.info("管理者へメール配信",res);}).catch(error=>{logger.error("メール配信エラー",error);});};最後に
おおまかに書きました。
詳細はGitHubをご確認ください。
もっと簡単な方法があるのだと思います。
↧
S3にCSVファイルがアップロードされるとLambdaがDynamoDBへデータを挿入します
概要
S3へjsonファイルがアップロードされるとLambdaがそのファイルの中身を解析して、DynamoDBへデータを挿入します。
jsonファイルの構成
dataキーに配列があり、配列の要素はオブジェクトとなっています。
{"data":[{"item1":"sample data1","item2":123,"item3":"test data1"},{"item1":"sample data2","item2":1234,"item3":"test data2"},]}主な流れ
- S3へファイルがアップロードされるとLambdaが起動
- アップロードされたファイルの中身を取得
dataキーから配列を取得- 配列を
forEachで各要素をDynamoDBへPUTするためのパラメーター化 - さらにパラメーター化したオブジェクトを配列に格納
- その配列を
batchWriteするためにパラメーター化 batchWriteメソッドで一気にDynamoDBへ書き込み
Lambdaのコード
indes.js
constS3=require('aws-sdk/clients/s3');consts3=newS3({apiVersion:'2006-03-01',region:'ap-northeast-1'});consts3Params={};constdynamodb=require('aws-sdk/clients/dynamodb');constdocClient=newdynamodb.DocumentClient({"convertEmptyValues":true});//convertEmptyValuesをtrueにすると空の値がtrueになる。(多分他の値にしたほうが良い)constTABLE_NAME=process.env.DYNAMO_TABLE_NAME;// 環境変数から取得するexports.handler=async(event)=>{console.log('Received event:',JSON.stringify(event,null,2));constkey=event.Records[0].s3.object.key;constbucket=event.Records[0].s3.bucket.name;console.log(bucket,key);s3Params.Bucket=bucket;s3Params.Key=key;try{constdata=awaits3.getObject(s3Params).promise();constjsonBody=data.Body.toString();// toString()しないとBuffer形式になるconstorders=JSON.parse(jsonBody).data;constrequestArry=[];orders.forEach(order=>{constrequestObj={PutRequest:{Item:order}};requestArry.push(requestObj);});constdynamoBatchPrams={RequestItems:{[TABLE_NAME]:requestArry}};awaitdocClient.batchWrite(dynamoBatchPrams).promise();console.log('Success DynamoDB PutRequest!');}catch(error){console.log(error);}};Lambdaの設定
環境変数
DynamoDBのテーブルを作成したらLambdaの環境変数へテーブル名を入力してください。
Lambdaの実行ロール
デフォルトの設定で作成後、IAMコンソールでDynamoDB FullAccessのポリシーを追加してください。
トリガーの追加
S3を選択して、バケットとイベントタイプを選択して、トリガーを追加してください。
DynamoDBのテーブル
DynamoDBのテーブルは名前とプライマリーキーを設定して作成してください。
最後に
複数のレコードを書き込む際はPUTではなく、batchWriteメソッドが良いと思われます。
↧
↧
Elixirのノード、プロセス間通信
はじめに
プログラミングElixirの「15.2 プロセスの名前付け」を理解するための備忘録です。
概要:とあるコールバックプロセスのPIDを登録し、そのPIDに対して2秒間隔でメッセージを送信するプログラム
異なるノードからコールバックプロセスを登録できるようにする。
参考
プログラミングElixir「15.2 プロセスの名前付け」
環境
- IEx 1.9.1 (compiled with Erlang/OTP 22)
目次
- ソース
- ノード1で実行
- ノード2で実行
- まとめ
ソース
ticker.ex
defmoduleTickerdo@interval2000# 2 seconds@name:tickerdefstartdo# 関数generatorのプロセスを開始pid=spawn(__MODULE__,:generator,[[]])# 開始した関数generatorを名前「ticker」として登録:global.register_name(@name,pid)enddefregister(client_pid)do# ticker(関数generator)に{ :register, client_pid }を送信send:global.whereis_name(@name),{:register,client_pid}enddefgenerator(clients)doreceivedo# 関数registerから呼ばれた場合に実行{:register,pid}-># codeIO.puts"registering #{inspectpid}"generator([pid|clients])after# 2秒間隔で実行@interval->IO.puts"tick"Enum.eachclients,fnclient-># モジュールClientの関数receiverへメッセージ「:tick」を送信sendclient,{:tick}end# 再帰generator(clients)endendenddefmoduleClientdodefstartdo# 関数receiverのプロセスを開始pid=spawn(__MODULE__,:receiver,[])# 関数registerを実行(pid=receiver)Ticker.register(pid)enddefreceiverdoreceivedo# 関数generatorからのメッセージ受信{:tick}-># codeIO.puts"tock in client"# 再帰receiverendendendノード1で実行
%iex--snameoneiex(one@kochiex)1>c("ticker.ex")[Client,Ticker]iex(one@kochiex)2>Node.connect:"two@kochiex"trueiex(one@kochiex)3>Node.list[:"two@kochiex"]iex(one@kochiex)4>Ticker.start:yestickticktickiex(one@kochiex)5>Client.startregistering#PID<0.128.0>{:register,#PID<0.128.0>}ticktockinclientticktockinclientticktockinclientticktockinclient# Node twoでClient.startを実行registering#PID<15299.123.0> ticktockinclientticktockinclientノード2で実行
%iex--snametwoiex(two@kochiex)1>c("ticker.ex")[Client,Ticker]iex(two@kochiex)2>Node.list[:"one@kochiex"]iex(two@kochiex)3>Client.start{:register,#PID<0.123.0>}tockinclienttockinclientまとめ
次回はGenServer の つもり。
↧
Hueを使って照明の色で天気予報を認識する
1. 億劫なこと
毎日、テレビやスマホで天気予報を確認して服装の選択や傘の有無を考えるのがめんどくさい。
2. やりたいこと
当日の天気予報をAPIで取得し、天気・温度に応じて室内照明(Hue)の色を点灯させたい。
想定する手順は以下の通り。
- 気象情報APIによって、当日の情報(天候と気温)を取得する
- 取得した天気の情報を元に、照明の色を変化させる
3. 環境
- node version : v8.11.3
- Philips Hue Go + ブリッジ
4. 実装
4.1 準備
モジュールのインストール。
$ npm install request
4.2 気象情報APIの利用
今回は無料のAPIを使いたかったため、openweathermapを利用した。
HPから利用登録してAPPIDを入手。
天気の情報は以下のAPIによってGETできる。
http://api.openweathermap.org/data/2.5/weather?zip=[郵便番号],JP&units=metric&APPID=[APPID]
コードは以下の感じ(郵便番号とAPPIDは任意に設定)。
weather.js
// ▼▼天気情報を取得(openweathermapのAPI)▼▼
var request = require('request');
// API情報(zip_codeとwAPPIDは任意)
var wbaseurl = "http://api.openweathermap.org/data/2.5/weather";
var zip_code = "100-0005,JP"; //東京駅の郵便番号
var wAPPID = [任意のID];
var openweather_api = wbaseurl + "?zip=" + zip_code + "&units=metric&APPID=" + wAPPID;
var options_openweather = {uri: openweather_api, method: 'GET'};
function openweather_get() {
request(options_openweather, function (error, response, body) {
var temp_json = JSON.parse(body).main.temp;
console.log("本日の気温:" + temp_json + "度");
var weather_json = JSON.parse(body).weather[0].main;
console.log("本日の天気:" + weather_json);
});
return
}
openweather_get()
4.3 Hueの制御
HueのAPIについて
Hueの登録とAPIは公式ページを参考にして登録を行った。HueのAPI制御
次に、HueのAPIを制御するために以下のようなコードを書いた(ipaddressとusernameは任意に設定)。
hue.js
// ▼▼Hueの制御▼▼
var request = require('request');
// HueのAPI情報(ipaddressとusernameは任意)
var hue_uri = "http://[ipaddress]/api/[username]/lights/1/state";
// Hueを「白」に光らせる
var hue_headers = {"Content-type": "application/json"};
var white = {"on":true, "bri":144, "hue": 22612, "xy":[0.3146,0.3303], "effect": "none", "sat":171};
var options_W = {uri: hue_uri, method: 'PUT', headers: hue_headers, json: white};
function white_hue() {
request(options_W, function (error, response, body) { console.log(body);})
return
}
white_hue()
色は「白」以外にも、条件に応じて様々なパターンを作成した。
4.4 条件の設定
4.4.1 温度情報に応じて色を変化
温度ごとの条件は以下のように設定した。
30度以上 → 赤色に点灯
20度以上で30度未満 → 緑色に点灯
10度以上で20度未満 → 水色に点灯
10度未満 → 青色に点灯
4.4.2 天気情報に応じて色を変化
APIで取得できる天気の条件は以下。
晴:"Clear", 曇:"Clouds", 雪:"Snow", 雨:Rain, 雷雨:"Thunderstorm", 霧雨:"Drizzle"
これを元に、天気ごとの条件を設定した。
晴れ or 曇り → 白色に点灯
それ以外(雨や雪) → 紫色に点灯
4.5 実行
天気情報APIの取得コードとHueの制御コードを、条件設定に合わせて一部改修して実装した。
写真は温度が寒く、天候が晴れの時の様子。

温度と天候の照明色は、30秒ごとに交互に点滅するようにした。
正常な動作を確認できたのでサーバーに実装し、毎日の外出時刻に合わせて点灯するように設置した。
5. まとめ
照明の色を見るだけで朝の支度ができるようになった。
理想は勝手に服や傘が準備されていることなのだが(笑)
でも、夕方の雨予報などはわからない、、、もっと良い使い方を検討してみたい。
↧
JavascriptのDate.prototype.toString()系まとめ
new Date()からタイムスタンプを作ってファイル名にしたい時、どのフォーマットにするか毎回調べてるのでまとめる
| メソッド | 出力される文字列 | 備考 |
|---|---|---|
| new Date('2000-01-01 00:00:00').toString() | "Sat Jan 01 2000 00:00:00 GMT+0900 (日本標準時)" | |
| new Date('2000-01-01 00:00:00').toISOString() | "1999-12-31T15:00:00.000Z" | |
| new Date('2000-01-01 00:00:00').toLocaleString() | "2000/1/1 0:00:00" | |
| new Date('2000-01-01 00:00:00').toGMTString() | "Fri, 31 Dec 1999 15:00:00 GMT" | 非推奨 .toUTCString()を使う |
| new Date('2000-01-01 00:00:00').toUTCString() | "Fri, 31 Dec 1999 15:00:00 GMT" | |
| new Date('2000-01-01 00:00:00').toDateString() | "Sat Jan 01 2000" | |
| new Date('2000-01-01 00:00:00').toLocaleDateString() | "2000/1/1" | |
| new Date('2000-01-01 00:00:00').toTimeString() | "00:00:00 GMT+0900 (日本標準時)" | |
| new Date('2000-01-01 00:00:00').toLocaleTimeString() | "0:00:00" |
おまけ
moment.jsでお手軽にタイムスタンプを作りたいとき(よくやる)
// const moment = require('moment');importmomentfrom'moment';constnow=moment().format('YYYY-MM-DD HH:mm:ss.SSS');now;// 2000-01-01 00:00:00.000hourを00~23で表したいときは、大文字でHH
小文字でhhだと1~12になってしまう
↧
ubuntu18.04でnpm testを使いava実行すると「SyntaxError: Unexpected token {」エラーが出てしまうときの解決方法
なんてことないことでしたがNode.js, npm, avaを使い初めて日も浅くて2~3時間悩んだのでメモです。あまりいないかもしれないですが、他に同現象で困っている人がいたら役立ちますように。
現象
初めてavaを使おうと https://www.npmjs.com/package/avaに従ってnpm testをすると以下のエラーとなってしまい実行できない。
$ npm test> ava -v(node:5301) UnhandledPromiseRejectionWarning: /home/shohei/tmp/20200203/shoheihagiwara-cli/node_modules/ava/lib/node-arguments.js:9
} catch {
^
SyntaxError: Unexpected token {
at createScript (vm.js:80:10)
at Object.runInThisContext (vm.js:139:10)
at Module._compile (module.js:616:28)
at Object.Module._extensions..js (module.js:663:10)
at Module.load (module.js:565:32)
at tryModuleLoad (module.js:505:12)
at Function.Module._load (module.js:497:3)
at Module.require (module.js:596:17)
at require (internal/module.js:11:18)
at Object.exports.run (/home/shohei/tmp/20200203/shoheihagiwara-cli/node_modules/ava/lib/cli.js:261:33)(node:5301) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch().(rejection id: 1)(node:5301)[DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
環境
$ uname-v#30~18.04.1-Ubuntu SMP Fri Jan 17 06:14:09 UTC 2020$ node --version
v8.10.0
$ npm --version
3.5.2
$ grep ava package.json -C1"scripts": {"test": "ava -v"},
--"dependencies": {"ava": "^3.2.0"}$ cat test.js
const test= require('ava');test('foo', t =>{
t.pass();});test('bar', async t =>{
const bar = Promise.resolve('bar');
t.is(await bar, 'bar');});原因
ava 3 で Node.js v8 はサポートが切れているためです。(https://github.com/avajs/ava/releases)
他にもava のページには「avaがサポートするのはNode.jsがサポートするもののみ」と書かれていて、2020年2月時点で Node.js v8 自体がNode.jsでサポート切れになっています。(https://github.com/nodejs/Release#release-schedule)
解決方法
ava 3 がサポートする Node.js をインストールし実行し直します。
自分は v12 をインストールしました。
参照:https://github.com/nodesource/distributions/blob/master/README.md#installation-instructions
# インストール$ curl -sL https://deb.nodesource.com/setup_12.x | sudo-E bash -
$ sudo apt-get install-y nodejs
# バージョン確認$ node --version
v12.14.1
# 実行$ npm test> ava -v
? foo
? bar
2 tests passed
↧
↧
react-native のMetro bundlerでNodeエラーが出るときの対処
概要
React Native開発をしているとMetro Bundlerが上がってきます。
このときに自動で立ち上がってくるTerminal上のMetroでエラーが出た時の対処方法のメモとなります。
対象読者
- React Native v0.59.x >= 利用者
事象
React Native開発をしていると(古いバージョンでは)必ずMetro Bundlerのお世話になります。Metro Bundlerは react-native-cliのrun-iosコマンドを叩くなどすると上がってきます。
その際、新規PCで何気なく実行すると下記のエラーが出ました。
あれ?nodeがない?となりましたが、普段使いしているterminalで確認したところ下記の通り、nodeは入っていました。
$ node -v
v10.17.0
原因
NVMなどを使っていると、参照しているnodeはホームディレクトリ配下のことが多いです。
しかし、react-native run-iosで起動するターミナルが参照するNodeのPATHは/usr/local/bin/nodeのようです。
よって、自身が利用しているnodeのパスを確認して、/usr/local/bin/nodeへリンクを通してあげると解決します。
# nodeが存在することを確認できます$ which node
/home/USERNAME/.nvm/versions/node/v10.17.0/bin/node
# 上記パスに対して、シンボリックリンクをはります# $()とすることで()内コマンドの結果を利用できます$ ln-s$(which node) /usr/local/bin/node
参考リンク
↧
UbuntuでNode.jsとExpressの環境を作る
Ubuntu で Node.js と Express の環境を作って試してみる
Ubuntu の環境は既に作成済なのが前提
Node.js を動かす環境を作る
- 参考サイト→https://qiita.com/seibe/items/36cef7df85fe2cefa3ea
- とりあえず最新のを入れようとしてみる
下記を順番に入力したら完了
sudo apt install -y nodejs npm
sudo npm install n -g
sudo n stable
sudo apt purge -y nodejs npm
exec $SHELL -l
versionを確認するなら↓コレ
node -v
v12.14.1 とか出るはず
Node.js で Hello World してみる
node と入力して node を起動
↓こんなのが出る
Welcome to Node.js v12.14.1.
Type ".help" for more information.
>
以下を入力
console.log('Hello world')
出力を確認
Hello world
undefined
CTRL+Cを2回押すとvagrantターミナルに戻る
express を動かす環境を作る
フォルダ作成
mkdir (フォルダ名)
cd (フォルダ名) でフォルダ移動しとこう
- Package.jsonを作る
npm init
色々質問されるけど、最初は全部Enter押下でも良い
必要に応じて記入する
- express をインストール
以下を実行
npm install express --save
これでようやく express が使える
express に hello world させる
先ほど作ったフォルダに移動
cd (フォルダ名)
- app.js を作る
- nano と入力してテキストエディタを起動 (他のテキストエディタが良いならそれでも可)
↓コレを入力(orコピペ)して、 app.js として保存
app.js
constexpress=require('express')constapp=express()app.get('/',(req,res)=>res.send('Hello World!'))app.listen(3000,()=>console.log('Example app listening on port 3000!'))- node app.js を起動
コンソールには↓こんなのが出る
Example app listening on port 3000!
GUIのUbuntu-Desktopがあれば、
ブラウザで http://localhost:3000/にアクセスすると、
Hello World! がブラウザに表示される。
IPの設定は以前書いたやつのVagrantfileで設定してたはずなので、
そのままだったら、 http://192.168.123.222:3000/にアクセスしたら、
Hello World! がブラウザに表示される。
これで完了。
あとは MySQL との接続&表示とかをしていけばいい。
参考
- Ubuntu に Node.js を入れる
- Ubuntu に express を入れる
- express で hello world してみる
↧
Docker 環境で nodemon が watch してくれない問題と対処方法
Web アプリの開発環境を Docker で作っていたところ、nodemon がうまくファイル変更を検出してくれなくて困ったので、そのときのメモ。
マウントしたボリュームだと nodemon が watch してくれない問題
問題を再現するために、以下の3つのファイルを用意する。
ポイントとしては、ホストのディレクトリをコンテナ内にマウントしてそれをコンテナ内の nodemon が watch しているということ。
Dockerfile
FROM node:12ADD . /appWORKDIR /appCMD ["node", "."]index.js
consthttp=require('http')http.createServer((req,res)=>{res.writeHead(200,{'Content-Type':'text/plain'})res.end('ok')}).listen(80)docker-compose.yml
version:'3'services:app:build:.ports:-8080:80volumes:-.:/appcommand:npx nodemondocker-compose upでコンテナを起動し、Web ブラウザから http://localhost:8080/にアクセスすると okと表示されるはず。
この開発用コンテナは nodemon から node プロセスを起動しているので、 index.jsが編集された場合には自動で restart してほしい。
しかしこの場合、いくら index.jsを編集しても nodemon はその変更を検出してくれない。
Chokidar が Polling するように設定する
nodemon はファイル監視のために内部で Chokidarを利用しており、そのドキュメントにはこのように書いてある。
usePolling (default: false). Whether to use fs.watchFile (backed by polling), or fs.watch. If polling leads to high CPU utilization, consider setting this to false. It is typically necessary to set this to true to successfully watch files over a network, and it may be necessary to successfully watch files in other non-standard situations. Setting to true explicitly on MacOS overrides the useFsEvents default. You may also set the CHOKIDAR_USEPOLLING env variable to true (1) or false (0) in order to override this option.
ネットワーク経由でファイルを監視する場合にはポーリングするように設定する必要があるらしい。
docker-compose.yml
+ environment:
+ CHOKIDAR_USEPOLLING: 1
というわけで環境変数 CHOKIDAR_USEPOLLING=1を設定した上で再試行したところ、無事にファイル変更を検出してくれるようになった。
めでたしめでたし。
↧
なぜ僕たちはサーバレスでJavaを諦めTypescriptを採用したか
この記事は個人ブログのうち技術に関する箇所のみを抜粋した転載です。
なぜ僕たちはサーバレスでJavaを諦めTypescriptを採用したか -Junks, GC cannot sweep-
またブログには書いたのですが、諸事情により先に英語版が存在します。
こちらも書いたのは僕なので、剽窃などではないことはご了承ください。
[元記事]: Why we replaced Java with Typescript for Serverless in dev.to
はじめに
サーバレス(serverless)は昨今もっとも注目を集める設計手法の一つで、おそらく多くの開発者が大なり小なり自分のプロダクトに応用し始めているのではないでしょうか?
僕自身、完全にサーバレスに魅せられてしまい、昔ながらの自分でサーバやミドルウェアを管理しながら運用するみたいな世界には戻れる気がしません。
そもそもスケーリングや分散可能性をきちんと考えて設計されたアプリケーションであれば、旧来のサーバーアプリケーションの機能から受けられる恩恵も比較的少なくなりますし、サーバレスに切り替えるデメリットはそこまでありません。
最近は設計に関して相談された時は、必ずサーバレスの話題を出してみることにしています。
さて、サーバレスは既存の開発手法とは大きく異なるため、今持っている知識を刷新し、既存の手法や技術スタックを見直しながら開発していく必要があります。
見直しというからには、開発基盤として何の言語を使うかも、当然ながら見直さなくてはいけない技術スタックの対象になります。
タイトルにある通り、最終的に僕たちはTypescriptを採用し、およそ一年半開発・メンテナンスを行ってきました。
そして一年半経った今、あくまで個人的な感想ではありますが、Typescriptは僕たちが期待した以上に成果を出してくれました。
そこでこの記事では、以前使用していた言語にどんな問題があったのか、そしてなぜTypescriptに切り替えたことでどんな恩恵があったのかをこの記事では解説していきたいと思います。
なぜJavaを諦めなくてはならなかったのか
さて、なぜTypescriptを採用したかについて話す前に、まずなぜ以前使用していた非常に強力な言語であるJavaを諦めなくてはいけなかったかについてお話ししたいと思います。
NOTE
先に述べておきますが、僕は結構なJava好きです。なんなら初めて触った言語もJavaでした。
JVMに関してもそれなりに勉強して、その神がかったランタイムの仕組みにかなり感銘を受けています。(てか多分作ったやつは神)
なので、どこかの大学生のようにJavaがクソだとかレガシーだとか使い物にならんとか、この記事でそういうことを言うつもりは一切ありません。
また、そういったコメントもあまり嬉しくないです。あくまでサーバレスという仕組みにJavaがあまり合わなかっただけなので。
その点だけはご了承いただければ幸いです。
さて、本題に戻りましょう。
僕たちのサービスでは、サーバサイドはサービス設立当時から基本的にJavaだけで書かれていました。
当然ながらすでにJavaには多くの利点があり、特に
- プラットフォームフリー
- よくできたJITコンパイル
- やばいGC
- よく構成された文法
- 静的型付け
- 関数型サポート(最近は特に)
- 多様なライブラリ
- 信頼できるコミュニティ(Oracleではなく、開発者の方)
などなど挙げればきりがありません。
しかし、AWS Lambda上でコードを試していて気づいたのですが、Javaはあまりサーバレスに向かないことがわかりました。
理由としては以下のことが挙げられます。
- JVMの起動オーバーヘッドが大きい
- Springフレームワークを使用してるとさらにエグくなる
- 最終的なパッケージアーカイブがでかすぎる(でかいのは100MB以上)
- 関数が増えてくるとWebフレームワークなしでリクエストを捌くのがきつくなる
- コンテナは30分程度しか走らないため、G1GCやJITなどのJavaの利点が生かせない
- Lambdaは基本的にEC2上に建てられたAmazon Linuxのコンテナで動くため、プラットフォームフリーは関係ない。 (欠点ではないけど)
上述の点は全てなかなかに厄介ですが、今回は特に厄介だった問題についてもう少し書いてみたいと思います。
Cold Startがまじで厄介
一番厄介だったのは、圧倒的にCold Startのオーバーヘッドです。おそらく多くの開発者の方々もこいつに悩まされているのではないかと思います。。。
僕たちはコンピューティング基盤としてAWS Lambdaを使っていたのですが、AWS Lambdaはユーザからのリクエストが来るたびに新しいコンテナを立ち上げます。
一度立ち上がってしまえば、しばらくは同じコンテナインスタンスを再利用してくれるのですが、初回起動時にはJavaのランタイムに加え、フレームワークで利用されるDIコンテナやWebコンテナなども全て初期化する必要があります。
さらに言えば、一つのコンテナで処理できるのはあくまで一つのリクエストのみで、複数のリクエストを処理することはできません。(内部で数百のリクエストスレッドをプーリングしてたとしても同じです。)
つまりどういうことかというと、もし複数のユーザがリクエストを同時に送ってきた場合、Lambdaは起動中のコンテナの他に、別のコンテナを起動しなくてはいけなくなるということです。
通常、僕たちはどの時間に具体的に何軒のリクエストが同時に来るかを事前に予測することはできません。
つまり、何らかの仕組みを作ったとしても、事前に全てのLambdaをhot standbyさせることはできないのです。
これは必然的にユーザに数秒から10秒以上の待機時間を強制し、ユーザビリティを著しく下げることにつながります。
こんな感じでCold Startがえげつない事を理解した僕らは、これまでの数年かけて書かれた技術スタックを捨てて、他の言語を選択することを決めました。
なぜTypescriptを選んだのか
めちゃくちゃ恥ずかしい話なのですが、正直Lambdaでサポートされている全ての言語をきちんと精査・比較して決めたわけではないのです。
ただ、正直な話、状況的にTypescript以外の選択肢はなかったのです。
まず第一に、動的型付け言語は外しました。長期に渡ってスキルのバラバラな開発者によって保守・メンテ。拡張されるコードなので、動的型付けはあまり使いたくありません。
したがって、PythonとRubyに関してはかなり序盤で選択肢から外れました。
C#とGoに関しても、現在ほとんどのチームがJavaをメインに開発しているサービスなので、既存言語とあまりかけ離れた言語を使うと新規開発者のジョインが難しくなると判断し、今回は見送られました。
もちろん、昨今この二大言語は非常に注目度が高く、特にGolangに関しては徐々にシェアを伸ばしつつあるのは知っています。
しかし、急いでサーバレスに開発を移す必要があったため、僕たち自身のキャッチアップの時間も考慮し、見送らざるを得なかった感じでした。
Typescriptの利点
という事で、僕たちはTypescriptを使い始めたわけです。
Typescriptの利点を挙げるとしたらこんな感じでしょうか?
- 静的型付け
- 小さいパッケージアーカイブ
- ほぼ0秒の起動オーバーヘッド
- Javaとjavascriptの知識が再利用できる
- NodeJSのライブラリやコミュニティが使える
- javascriptと比べても関数型プログラミングがしやすい
- ClassとInterfaceにより構造化されたコードが描きやすい
長期に渡って運用・開発が行われるプロジェクトにおいて静的型付け言語がどれだけ大きな恩恵を与えるかは今更語るまでもありませんので、ここには書きません。
ここでは主に、Typescriptのどういった点がサーバレス開発によく馴染んだかについて書いていきたいと思います。
静的型付け以外にもTypescriptを使う利点は非常に大きく、
小さいパッケージと小さい起動オーバーヘッド
おそらくサーバレスでTypescriptを使う利点という観点からいうとこれが一番大事だった気がします。(なにせ他のメリットはほぼTypescript自体のメリットなので・・・)
先ほど触れた通り、JavaはJVM本体やフレームワークが利用するDI/Webコンテナなどの起動にかかるオーバヘッドが非常に大きいです。
加えて、Javaの性質上、AWS Lambdaで流すには以下の
Additionally, as the nature of Java, it has the following weak point to be used in the AWS Lambda.
マルチスレッドとそれを取り巻くエコシステム
マルチスレッドは非常に強力な機能であり、事実として僕たちはこの機能のおかげで多くのパフォーマンス問題を解決してきました。
JVM自体もガーベージコレクションやJITコンパイルにおいて、デフォルトでにマルチスレッドを活用してあの素晴らしいランタイムを実現してます。
(詳しくはG1GCやJIT Compileを参照)
しかし、起動時間単体で見ると、アプリケーションに使用する全てのスレッドを立て終わるまでに、100ミリ秒から数秒かかっていることがわかります。
この機能自体は旧来のいわゆるクラサバモデルでEC2上で動くアプリケーションならほぼ無視できるオーバーヘッドですが、LambdaなどのFaaS上で動くサーバレスアプリケーションでは決して無視できません。
Typescriptはnodejsベースであり、基本的にシングルスレッドです。非同期は別スレッドや別プロセスではなくあくまでジョブキュー、イベントループなどで管理されます。
したがって、ほとんどのライブラリやフレームワークは起動時にスレッド展開をする必要はありませんし、ランタイムを起動するためのオーバーヘッドもほとんどかかりません。
巨大なパッケージアーカイブ
サーバレスにおいてソースコードのパッケージアーカイブは、基本的に小さいに越したことはありません。
Lambdaのコンテナは起動時、AWSにより管理されたソースコード用のS3バケットからソースをダウンロードし、コンテナに展開します。
S3からのダウンロード時間は通常非常に短時間ですが、100MBや200MBとなると無視はできません。
NodeJsのパッケージは基本的にJavaに比べて小さくなります。
正直なんでそうなるかに関しては不勉強でわかっていないのですが、以下の理由が関係してるんじゃないかなと思ったりします。(もしこれやでっていうのをご存知の方はコメントで教えてください)
- Javaのフレームワークやライブラリは包括的なものも多く、本来使いたい機能に必要ない依存性を引き込んで来るが、javascriptは目的特化のライブラリが多く、必要最低限に依存を抑えられることが多い。
- Javascript(nodejs)は1ファイルに複数のmoduleを書くことができ、それでいてメンテもしやすいが、Javaにおけるメンテナンス性の重要なポイントはファイル分割とパッケージ管理のためソースが肥大化しやすい。
実際Javaで書いていた時は最大で200MB以上のパッケージができることもあったのですが、nodejsに変えてからは35MB程度で済んでいます。
この巨大なパッケージアーカイブは、僕たちがSpringで書かれた旧来のコードを再利用しようとしたのが大きな原因なのですが、実際これらのいらないフレームワークを除いて最適化したコードでも、どうしても50MBは必要になってしまいました。
Javascriptの知識やエコシステムを利用できる
僕たちもWeb開発者のため、基本的にフロントエンドも書きます。したがって、ある程度のjavascriptやnodejsに関する知識は蓄えていました。
Jquery全盛時代からReact/Vueのようなモダンフレームワークでの開発までを通じて、言語的な特徴はある程度抑えていましたし、どうやって書けばいいコードになるかもある程度理解してるつもりです。
Typescriptはjavascriptの拡張言語であり、最終的にはjavascriptにトランスパイルされます。
多くの文法やイディオムはjavascriptから受け継がれているので、実際それほど準備期間を要さずにサービス開発を始められました。
加えて、ほとんどのメジャなNodeJSのライブラリはTypescriptに必要な型定義を提供しているので、NodeJSのエコシステムのメリットをそのまま享受できたのも非常に嬉しいポイントでした。
関数型の実装が非常にしやすい
昨今の技術トレンドを語る上で、関数型の台頭はなくして語ることはできません。
関数型の実装はその性質上、シンプルでテスト可能で危険性の低い安定したコードを書くのに大きく寄与します。
特にAWS Lambdaの場合、常に状態を外部化するコードが求められるため、状態や副作用を隔離する関数型の実装は非常に相性が良く、メンテもしやすくなります。
そもそも、jqueryの生みの親であるJohn ResigがJavaScriptニンジャの極意で語ったように、javascriptはそもそも関数型のプログラミングをある程度サポートしています。
javascriptにおいて関数は関数は第1級オブジェクトであり、jqueryも実は関数型で書かれることを期待して作られています。
しかし一方で、動的型付け言語で関数型のコードを書こうとすると、時折非常にめんどくさい事になることがあります。
例えば、プリミティブ型だけで表現できる関数は非常に限られますし、返り値や引数にObjectを取るのは普通に結構危険です。
しかしtypescriptでは引数や返り値に型を指定することができます。
加えて、以下のTypescriptの機能は、僕たちの達の書く関数の表現の幅を広げ、より安全でシンプルなコードを書くのに寄与してくれます。
- Type: 共通に使用される型をコンテクストに合わせて型付けできる。(stringとUserIdやPromiseとResponseなど)
- Interface/Class: Objectで表現されるの引数や返り値をコンテクストにあった型で表現できる。
- Enum: よもや語る必要もあるまい
- Readonly: 自分で作成した型をImmutableに出来る
- Generics: 関数のインターフェイスの表現の幅が広がる
Typescriptは他にも関数型で書こうとした時に非常に便利な機能をいろいろ備えていますが、全てをここであげることはしません。(っていうか、結構javascript由来のものが多い)
関数型とTypescriptに関する記事は今後どこかで書いていきたいなと思っています。
Javaで学んだBest Practiceを再利用できる
typescriptの文法を学ぶと、かなりJavaやScalaに似通った記述ができることに驚きます。
僕たちはそもそも、それなりの期間をJavaで開発してくる中で、Javaにおけるいいコードのお作法をある程度蓄積してきました。
ClassやInterfaceをどう設計すべきか、enumはどう使うと効率的か、Stream APIはどう書くと保守性が上がるかなど、蓄積してきたノウハウはそれなりに捨てがたいものがありました。
Typescriptはインターフェイスやクラスに加えて、アクセスモディファイアやreadonly(Javaでいうfinalのプロパティ)をサポートしており、僕たちは割とさらっとJavaで育んだノウハウをそのまま導入することができました。
これにはオブジェクト指向的なベストプラクティスやデザインパターンなども含まれます。
(関数指向とオブジェクト指向は二律背反ではないので、プロジェクト内で同時に使用されても問題ないと考えています。個人的には。)
もし僕たちがやや文法が独特なPythonやRubyを採用していたとしたら、より品質の高いコードを書くためのプラクティスをどうこの言語に応用すべきかに多くの時間を費やすこになったことかと思います。(それも楽しいんですよ、知ってます、ただ時間がね。。。。)
当然ながら全ての設計やロジックをコピペしたわけではないですし、むしろ大半のコードを書き直ししました。
ただ、おおよその部分をスクラッチで書き直した割に、それなりの品質でそれなりの短期間で書き直しが終わったんだよということは特筆しておくべきかと思います。
結論
僕たちもまだまだTypescriptに関しては初心者といっていいレベルでまだまだ勉強が必要ですが、すでにそのメリットは全力で享受しておりいます。
今聞かれれば、Golangもいいなあとか、MicronautとGraalVMとかも面白そうだなあとか、もっと他の選択肢もあったかもなあとか考えたりもするのですが、現状Typescriptには非常に満足しており、最善の選択肢の一つではないかと信じています。
もちろん、処理遅いけどバッチ処理どうすんねんとか、並行処理とか分散処理同すんねんとか、、ワークフロウどう設計すんねんとか、API Gatewayのタイムアウトどうハンドルするねんとか、データの一貫性どう担保すんねんとか、サーバレスやTypescriptに起因する問題にはたくさんぶち当たりました。
ただ、それはそれでギークとして非常に楽しく取り組んできて、すでにいくつかのこれが今の所best practiceじゃね?っていう方法もいくつか見つけました。(これはのちのち記事にしていきたい。)
もし今Javaでサーバレスに取り組んでいて、サーバレスくそやん、きついやん、やっぱ普通にサーバ欲しいわってなっている方がいたら、ぜひTypescriptも試してみてください。想像する以上に生産性出るんじゃないかなぁって期待してます。
長文おつきあいいただきありがとうございました。何かコメントや訂正があればぜひお願いします。
↧
↧
画像に対して顔検出を行いマスクする(opencv/opencv4nodejs/Node.js)
動機
インカメラで人物や顔写真入り証明書を撮影したエビデンス画像に対して、顔部分のマスクを行うツールを作成したかった。
言語選定
画像処理ライブラリ opencvの対応言語は C/C++JavaPythonです。
今回の動機であるツール的に用いるならば、Pythonが適していると思います。サンプルコードもたくさんあります。しかし、自分がPythonに対する知識が少なく、時間がかかりそうで逡巡していました。
しかし、opencv を Node.js 環境から使えるライブラリopencv4nodejsを見つけたので、試してみることにしました。
落とし穴
opencv4nodejsはopencvの型やメソッドと全く同じ名称ではなく、Javasciptの言語仕様に合わせて引数なども異なります。→ Contribution Guide
従って、Pythonのコードをそのまま置き換えればOK!といった形では実装できません。
自分はここを安易に考えていて若干ハマりました…
環境構築
Windows10(64bit)
Nodist(0.9.1) Node.js 11.13.0 上に
opencv4nodejs(5.5.0)をインストール
公式の手順はこちら
事前注意
- スペースを含むパスにインストールしない → node-gyp でパスが読めない
- 日本語を含むパスにインストールしない → opencvでパスが読めない
cmakeインストール
opencv4nodejs のインストール時に要求され、これが無いとエラーで進みません。
- cmakeをインストールする
- 実行ファイルがあるフォルダにPATHを通す 例:
G:\Program Files\CMake\bin
git
git ロングファイルネーム許可の設定(opencv4nodejs 内でのC++コンパイル用)git config --system core.longpaths true
npm
node-gypのインストール
npm install --global node-gypwindows-build-tools インストール
npm install --global windows-build-tools
※時間かかりますopencv4nodejs のインストール
npm install opencv4nodejs
※とても時間かかります
実装
TypeScriptで書いてます
顔検出
サンプルソースをそのまま使いました。opencv4nodejsではサンプルソースが充実していてます。
import*ascvfrom'opencv4nodejs';exportconstfeceMaskBlur=(imagePath:string)=>{// 対象画像読込constimage=cv.imread(imagePath);if(!image){thrownewError(`No file ${imagePath}`);}constclassifier=newcv.CascadeClassifier(cv.HAAR_FRONTALFACE_ALT2);// detect facesconst{objects,numDetections}=classifier.detectMultiScale(image.bgrToGray());if(!objects.length){thrownewError(`No faces detected! ${imagePath}`);}console.log('顔検出した領域:',objects);console.log('確度:',numDetections);// draw detectionletblurImage:cv.Mat;blurImage=image.copy();objects.forEach((rect,i)=>{// 顔検出した部分に対してマスクを実施blurImage=drawBlurRect(blurImage,rect,numDetections[i]);});// file 保存cv.imwrite(imagePath,blurImage);}検出した領域は、以下のような座標と大きさで取得できます
顔検出した領域: [ Rect { height: 525, width: 525, y: 1188, x: 1923 },
Rect { height: 262, width: 262, y: 3214, x: 2298 },
Rect { height: 584, width: 584, y: 878, x: 2714 } ]
確度: [ 8, 4, 11 ]
画像の一部上書き
上記で取得した領域に対して、マスクをかけます。
python だと、画像のデータは二次元配列として読み込まれるため、座標位置を指定して代入する形で記述できるようなのですが、opencv4nodejsだと形式が異なったため、ちょっと悩みました。
defmosaic_area(src,x,y,width,height,ratio=0.1):dst=src.copy()dst[y:y+height,x:x+width]=mosaic(dst[y:y+height,x:x+width],ratio)returndstdst_area=mosaic_area(src,100,50,100,150)cv2.imwrite('data/dst/opencv_mosaic_area.jpg',dst_area)Python, OpenCVで画像にモザイク処理(全面、一部、顔など)より引用
issueを検索して見つけました。
// 対象のRectを塗りつぶしconstdrawBlurRect=(image:cv.Mat,rect:cv.Rect,numDetection:number):cv.Mat=>{// 領域の切り出しconstsrcRoi:cv.Mat=image.getRegion(rect);// 切り出した部分にマスクをかけるconstmasked=cv.blur(srcRoi,newcv.Size(rect.width,rect.height));// 切り出した部分を元画像に合成masked.copyTo(image.getRegion(rect));returnimage;}実行
この画像に対して実行すると
こうなります
画像取得元
まとめと気づき
画像から何かを識別する場合には識別器を用い、OpenCVにはこの識別に使う学習済みファイルが準備されています。
今回は、Haar Cascade識別器(分類器)のhaarcascade_frontalface_alt2.xml→ コード中では cv.HAAR_FRONTALFACE_ALT2を使いました(サンプルそのまま)。
今回はインカメラを使った正面を向いた写真が基本なので顔検出がマッチしたのですが、横向きの顔は検出されにくい点については把握しておいた方がよさそうです。
参考
↧
node.jsのライブラリを作成したが、import構文でエラーが出る場合の対処法
ライブラリのpackage.jsonに
"type":
が存在しない場合、そのライブラリは、commonjsとして扱われ、importを使用するとエラーを吐く。
そのため、node.jsでライブラリを作成するときは、
"type": "module"
をライブラリのpackage.jsonに記述する必要がある。
この記述によりライブラリ内のコードは、es moduleとして扱われ importを使用可能になる。
参考
Node.js v13.7.0 Documentation
尚、Typeフィールドの値に関わらず.mjsファイルは、ES modulesとして扱われ、.cjsファイルはcommonjsとして扱われる。
↧
VSCodeを使って素朴に素朴にNode + TypeScript
学習用に。
必要なもの
事前に準備するもの
- Node.js
- VSCode
途中でインストールするもの
typescript
手順
1. npm init
いろいろ聞かれますが全部Enterで返事しておきます。
2. npm install typescript --save-devでTypeScriptのインストール
3. npx typescript --initでtsconfig.jsonを生成
4. 生成されたtsconfig.jsonをいじる
"sourceMap: true"の行は使いたいのでコメントアウト解除"outDir": "./"の行はコメントアウト解除して"outDir": "./dist"とでもしておきましょう。"rootDir": "./src"などとすることで、ソースファイルのルートディレクトリを設定できます。
あとはそのままでいいんじゃないかなと思います。必要になったら変更で。
5. VSCode上でビルドの設定をする
- エディタ上でコマンドパレットを開き(F1)、
task configure taskと入力 => 「テンプレートからtasks.jsonを生成」でEnter => 「Others」を選びます。要は./.vscode/tasks.jsonができればいいです。 - 下記を参考にビルドタスクを追加します。
labelはただの識別名なので適当で。
./.vscode/tasks.json
{//tasks.json形式の詳細についての資料は、//https://go.microsoft.com/fwlink/?LinkId=733558をご覧ください"version":"2.0.0","tasks":[{"label":"typescript build","type":"shell","command":"node ./node_modules/typescript/bin/tsc","group":"build"}]}6. VSCode上でデバッグの設定をする
- エディタ左側のメニューから虫アイコンをクリックし、
launch.jsonファイルを作成する - デバッグの種類を聞かれたらNode.jsを選択
- 生成された
launch.jsonをいじる"program": "${workspaceFolder}\\dist\\index.js"のように変更して、実行するJSファイルのパスを変更。typescriptにより生成されたファイルを実行したいので、distフォルダ内にある(これから作られるのでまだない)index.jsを指定。
デバッグする前にビルドしたいので、"preLaunchTask": "先ほど設定したタスクの適当な名前"を追記。
./.vscode/launch.json
{//IntelliSenseを使用して利用可能な属性を学べます。//既存の属性の説明をホバーして表示します。//詳細情報は次を確認してください:https://go.microsoft.com/fwlink/?linkid=830387"version":"0.2.0","configurations":[{"type":"node","request":"launch","name":"プログラムの起動","skipFiles":["<node_internals>/**"],"program":"${workspaceFolder}\\dist\\index.js","preLaunchTask":"typescript build"}]}ここまでで環境構築自体は終わりです。お疲れ様でした。参考までにHelloWorldします。
7. ./src/index.tsを作成
./src/index.ts
consthw:string='hello world';console.log(hw);あとはF5キーを押すことで、ビルド => 完了次第デバッグ開始されます。ブレークポイント置けば止まるし、普通にデバッグできます。
実体としてはかなり素朴な内容で、tscでビルドして、終わったらVSCode + Nodeのデバッガでデバッグするというものです。
VSCodeで「デバッグ前のタスク」を実行できるので、これを利用しています。
背景
Vue + TypeScriptをやったことがあるのですが、TypeScriptの設定はvue-cliに任せきりだったので、
Node.js + TypeScriptをシンプルに試してみたかったのでした。
参考
TypeScript + Node.js プロジェクトのはじめかた2019 - Qiita
筆者の環境
- Windows 10
- VSCode 1.14.1
- Node.js v8.12.0
↧
gRPC の使い方 (Node.js)
参考ページ
Node Quick Start
必要なライブラリーのインストール
sudo npm install grpc
sudo npm install @grpc/proto-loader
設定ファイル、サーバープログラム、クライアントプログラムの3つが必要です。
設定ファイル
helloworld.proto こちらと同じ
gRPC の使い方 (python)
サーバープログラム
greeter_server.js
varPROTO_PATH='helloworld.proto';vargrpc=require('grpc');varprotoLoader=require('@grpc/proto-loader');varpackageDefinition=protoLoader.loadSync(PROTO_PATH,{keepCase:true,longs:String,enums:String,defaults:true,oneofs:true});varhello_proto=grpc.loadPackageDefinition(packageDefinition).helloworld;functionsayHello(call,callback){console.error("*** sayHello ***")conststr_out='Test Hello '+call.request.nameconsole.error(str_out)callback(null,{message:str_out});}functionsayHello2(call,callback){console.error("*** sayHello2 ***")conststr_out='Test2 Hello again '+call.request.nameconsole.error(str_out)callback(null,{message:str_out});}functionmain(){varserver=newgrpc.Server();server.addService(hello_proto.Greeter.service,{sayHello:sayHello,sayHello2:sayHello2});server.bind('0.0.0.0:50051',grpc.ServerCredentials.createInsecure());server.start();}main();クライアントプログラム
greeter_client.js
varPROTO_PATH='helloworld.proto';vargrpc=require('grpc');varprotoLoader=require('@grpc/proto-loader');varpackageDefinition=protoLoader.loadSync(PROTO_PATH,{keepCase:true,longs:String,enums:String,defaults:true,oneofs:true});varhello_proto=grpc.loadPackageDefinition(packageDefinition).helloworld;functionmain(){varclient=newhello_proto.Greeter('localhost:50051',grpc.credentials.createInsecure());varuser;user='John';client.sayHello({name:user},function(err,response){console.log('Greeting:',response.message);});user='Tom';client.sayHello2({name:user},function(err,response){console.log('Greeting:',response.message);});}main();サーバープログラムの起動
export NODE_PATH=/usr/lib/node_modules
node greeter_server.js
クライアントプログラムの実行
$ export NODE_PATH=/usr/lib/node_modules
$ node greeter_client.js
Greeting: Test2 Hello again Tom
Greeting: Test Hello John
サーバーのコンソールには次のようなメッセージが出ます。
$ export NODE_PATH=/usr/lib/node_modules
$ node greeter_server.js
*** sayHello2 ***
Test2 Hello again Tom
*** sayHello ***
Test Hello John
↧
↧
【WebAudioAPI】録音した音声をバイナリデータ化、PHPへ受け渡し
概要
Node.js上で、IBMのWatsonによって人が話した音声データを自動で文字起こしするスクリプトを作成しました。
その中で、結構苦労した
PCのマイクに直接アクセス→録音した音声データをバイナリデータ化、PHPへ受け渡し
の部分をメモがてら貼り付け。
環境
$php -v
PHP 7.1.23 (cli) (built: Feb 22 2019 22:19:32) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.1.0, Copyright (c) 1998-2018 Zend Technologies
録音部分
hogehoge.js
// 音声データのバッファをクリアするaudioData=[];//様々なブラウザでマイクへのアクセス権を取得するnavigator.mediaDevices=navigator.mediaDevices||navigator.webkitGetUserMedia;//audioのみtrue。Web Audioが問題なく使えるのであれば、第二引数で指定した関数を実行navigator.getUserMedia({audio:true,video:false},successFunc,errorFunc);functionsuccessFunc(stream){constaudioContext=newAudioContext();sampleRate=audioContext.sampleRate;// ストリームを合成するNodeを作成constmediaStreamDestination=audioContext.createMediaStreamDestination();// マイクのstreamをMediaStreamNodeに入力constaudioSource=audioContext.createMediaStreamSource(stream);audioSource.connect(mediaStreamDestination);// 接続先のstreamをMediaStreamに入力for(letstreamofremoteAudioStream){try{audioContext.createMediaStreamSource(stream).connect(mediaStreamDestination);}catch(e){console.log(e);}}// マイクと接続先を合成したMediaStreamを取得constcomposedMediaStream=mediaStreamDestination.stream;// マイクと接続先を合成したMediaStreamSourceNodeを取得constcomposedAudioSource=audioContext.createMediaStreamSource(composedMediaStream);// 音声のサンプリングをするNodeを作成constaudioProcessor=audioContext.createScriptProcessor(1024,1,1);// マイクと接続先を合成した音声をサンプリングcomposedAudioSource.connect(audioProcessor);audioProcessor.addEventListener('audioprocess',event=>{audioData.push(event.inputBuffer.getChannelData(0).slice());});audioProcessor.connect(audioContext.destination);}録音した音声をバイナリデータ化
hogehoge.js
//音声をエクスポートした後のwavデータ格納用配列constwaveArrayBuffer=[];//仕様の関係で、大きなデータを分けたうちの1つのデータ容量が25MB以下になるよう制御if(audioData.length>250){constnum=audioData.length/250;constcount=Math.round(num);for(leti=0;i<count;i++){constsliceAudioData=audioData.slice(0,249);audioData.pop(0,249);constwaveData=exportWave(sliceAudioData);waveArrayBuffer.push(waveData);}}else{waveArrayBuffer.push(exportWave(audioData));} //PHPへPOSTvaroReq=newXMLHttpRequest();oReq.open("POST",'任意のパス',true);oReq.onload=function(oEvent){// Uploaded.};//複数のデータをblob化するための配列constblob=[];//waveArrayBufferに入っている複数のデータを1つずつ配列に格納waveArrayBuffer.forEach(function(waveBuffer){blob.push(newBlob([waveBuffer],{type:'audio/wav'}));})varfd=newFormData();for(leti=0;i<blob.length;i++){fd.append('blob'+i,blob[i]);}// oReq.setRequestHeader('Content-Type','multipart/form-data; name="blob" boundary=\r\n');//配列ごとリクエスト送信oReq.send(fd);functionexportWave(audioData){// Float32Arrayの配列になっているので平坦化constaudioWaveData=flattenFloat32Array(audioData);// WAVEファイルのバイナリ作成用のArrayBufferを用意constbuffer=newArrayBuffer(44+audioWaveData.length*2);// ヘッダと波形データを書き込みWAVEフォーマットのバイナリを作成constdataView=writeWavHeaderAndData(newDataView(buffer),audioWaveData,sampleRate);returnbuffer;}// Float32Arrayを平坦化するfunctionflattenFloat32Array(matrix){constarraySize=matrix.reduce((acc,arr)=>acc+arr.length,0);letresultArray=newFloat32Array(arraySize);letcount=0;for(leti=0;i<matrix.length;i++){for(letj=0;j<matrix[i].length;j++){resultArray[count]=audioData[i][j];count++;}}returnresultArray;}// ArrayBufferにstringをoffsetの位置から書き込むfunctionwriteStringForArrayBuffer(view,offset,str){for(leti=0;i<str.length;i++){view.setUint8(offset+i,str.charCodeAt(i));}}// 波形データをDataViewを通して書き込むfunctionfloatTo16BitPCM(view,offset,audioWaveData){for(leti=0;i<audioWaveData.length;i++,offset+=2){lets=Math.max(-1,Math.min(1,audioWaveData[i]));view.setInt16(offset,s<0?s*0x8000:s*0x7FFF,true);}}// モノラルのWAVEヘッダを書き込むfunctionwriteWavHeaderAndData(view,audioWaveData,samplingRate){// WAVEのヘッダを書き込み(詳しくはWAVEファイルのデータ構造を参照)writeStringForArrayBuffer(view,0,'RIFF');// RIFF識別子view.setUint32(4,36+audioWaveData.length*2,true);// チャンクサイズ(これ以降のファイルサイズ)writeStringForArrayBuffer(view,8,'WAVE');// フォーマットwriteStringForArrayBuffer(view,12,'fmt ');// fmt識別子view.setUint32(16,16,true);// fmtチャンクのバイト数(第三引数trueはリトルエンディアン)view.setUint16(20,1,true);// 音声フォーマット。1はリニアPCMview.setUint16(22,1,true);// チャンネル数。1はモノラル。view.setUint32(24,samplingRate,true);// サンプリングレートview.setUint32(28,samplingRate*2,true);// 1秒あたりのバイト数平均(サンプリングレート * ブロックサイズ)view.setUint16(32,2,true);// ブロックサイズ。チャンネル数 * 1サンプルあたりのビット数 / 8で求める。モノラル16bitなら2。view.setUint16(34,16,true);// 1サンプルに必要なビット数。16bitなら16。writeStringForArrayBuffer(view,36,'data');// サブチャンク識別子view.setUint32(40,audioWaveData.length*2,true);// 波形データのバイト数(波形データ1点につき16bitなのでデータの数 * 2となっている)// WAVEのデータを書き込みfloatTo16BitPCM(view,44,audioWaveData);// 波形データreturnview;}リクエスト受け取り部分(超絶一部抜粋)
hogehoge.php
//リクエスト受け取り$req=$_FILESvar_dump($req);//出力結果array(2){["blob0"]=>array(5){["name"]=>string(4)"blob"["type"]=>string(9)"audio/wav"["tmp_name"]=>string(14)"/tmp/ランダム文字列"["error"]=>int(0)["size"]=>int(509996)}おわりに
ご指摘等ありましたら宜しくお願い致します!
↧
Bot開発(Node.js)のDBアクセスライブラリは knex がオススメ!
Bot開発でNode.jsを使うことが多く、DBアクセスがある要件で pgなどで素のクエリを書いていて辛いなーと感じている時に、 knexに出会ったので紹介します。
公式ドキュメント http://knexjs.org/
GitHub https://github.com/knex/knex
使い方
インストール
$npm install--save knex pg
knex初期設定
$knex init
すると、以下のファイルが自動生成されます。
knexfile.js
// Update with your config settings.module.exports={development:{client:'postgresql',connection:{database:'linebot-dev',user:'zyyx-kubo',password:''},pool:{min:2,max:10},migrations:{directory:'./db/migrations',tableName:'knex_migrations'}},staging:{client:'postgresql',connection:{database:'my_db',user:'username',password:'password'},pool:{min:2,max:10},migrations:{directory:'./db/migrations',tableName:'knex_migrations'}},production:{client:'postgresql',connection:{database:'my_db',user:'username',password:'password'},pool:{min:2,max:10},migrations:{directory:'./db/migrations',tableName:'knex_migrations'}}};マイグレーションファイルの作成
$knex migrate:make create_user
Using environment: development
Created Migration: ./db/migrations/20190214205707_create_user.js
マイグレーション
実行
$knex migrate:latest
ロールバック
$ knex migrate:rollback
シード
ファイル作成
$knex seed:make test_users
Using environment: development
Created seed file: ./db/seeds/test_users.js
実行
$knex seed:run
Herokuでの実行
$heroku run knex migrate:latest --app app-name
↧
GraphQLでファイルアップロード
GraphQLでファイルアップロード
GraphQL(Appolo Server)でファイルをアップロードする。
サーバ側はnode.jsを使う。
クライアントはAltair GraphQL Clientと使う。
サンプルのソースコードは以下。
事前準備
Get started with Apollo Server - Apollo Server - Apollo GraphQL Docsに従う。
$ mkdir graphql-server-example ;\
cd graphql-server-example
$ npm init --yes
$ npm install apollo-server graphql
サーバ
File uploads - Apollo Server - Apollo GraphQL Docsをほぼそのまま使う。
若干の変更として、アップロードが成功したときにメッセージを表示するように変更。
file-uploads/index.js
const{ApolloServer,gql}=require('apollo-server');consttypeDefs=gql`
type File {
filename: String!
mimetype: String!
encoding: String!
}
type Query {
uploads: [File]
}
type Mutation {
singleUpload(file: Upload!): File!
}
`;constresolvers={Query:{uploads:(parent,args)=>{},},Mutation:{singleUpload:(parent,args)=>{returnargs.file.then(file=>{console.log(`📁 File get ${file.filename}`);returnfile;});},},};constserver=newApolloServer({typeDefs,resolvers,});server.listen().then(({url})=>{console.log(`🚀 Server ready at ${url}`);});サーバを起動する。
$ node file-uploads/index.js
🚀 Server ready at http://localhost:4000/
クライアント
アップロードするファイルの準備。
echo "FOO" > file-uploads/foo.txt
Altair GraphQL Clientでファイルをアップロードする。

それぞれ以下を入力しSend Requestを実行。
- URL
http://localhost:4000
- graphQL query
mutation($file: Upload!){
singleUpload(file: $file){
filename
mimetype
encoding
}
}
- Choose file
foo.txt
- File name
file
成功すればサーバに以下のログが出力される。
📁 File get foo.txt
↧